DITTY
User
-
Registriert
-
Letzter Besuch
Alle Beiträge von DITTY
-
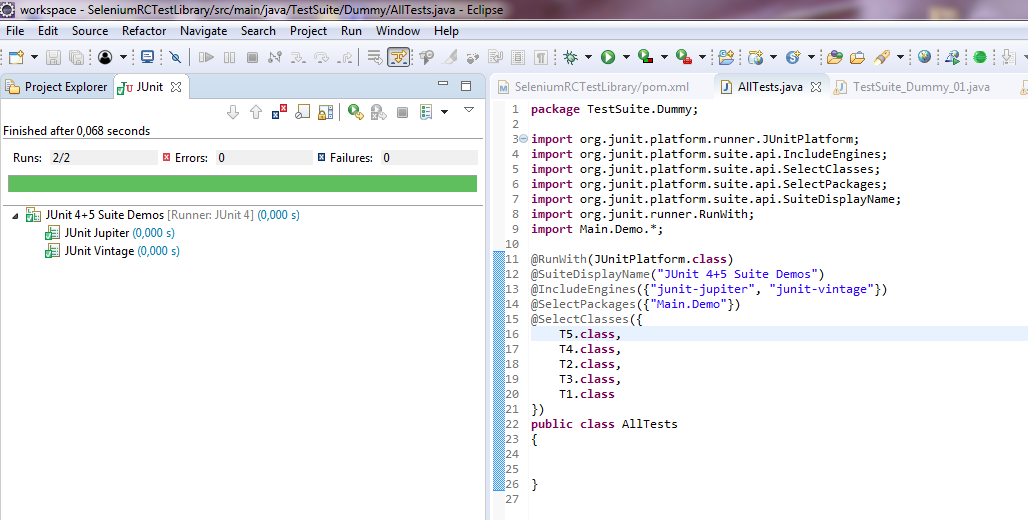
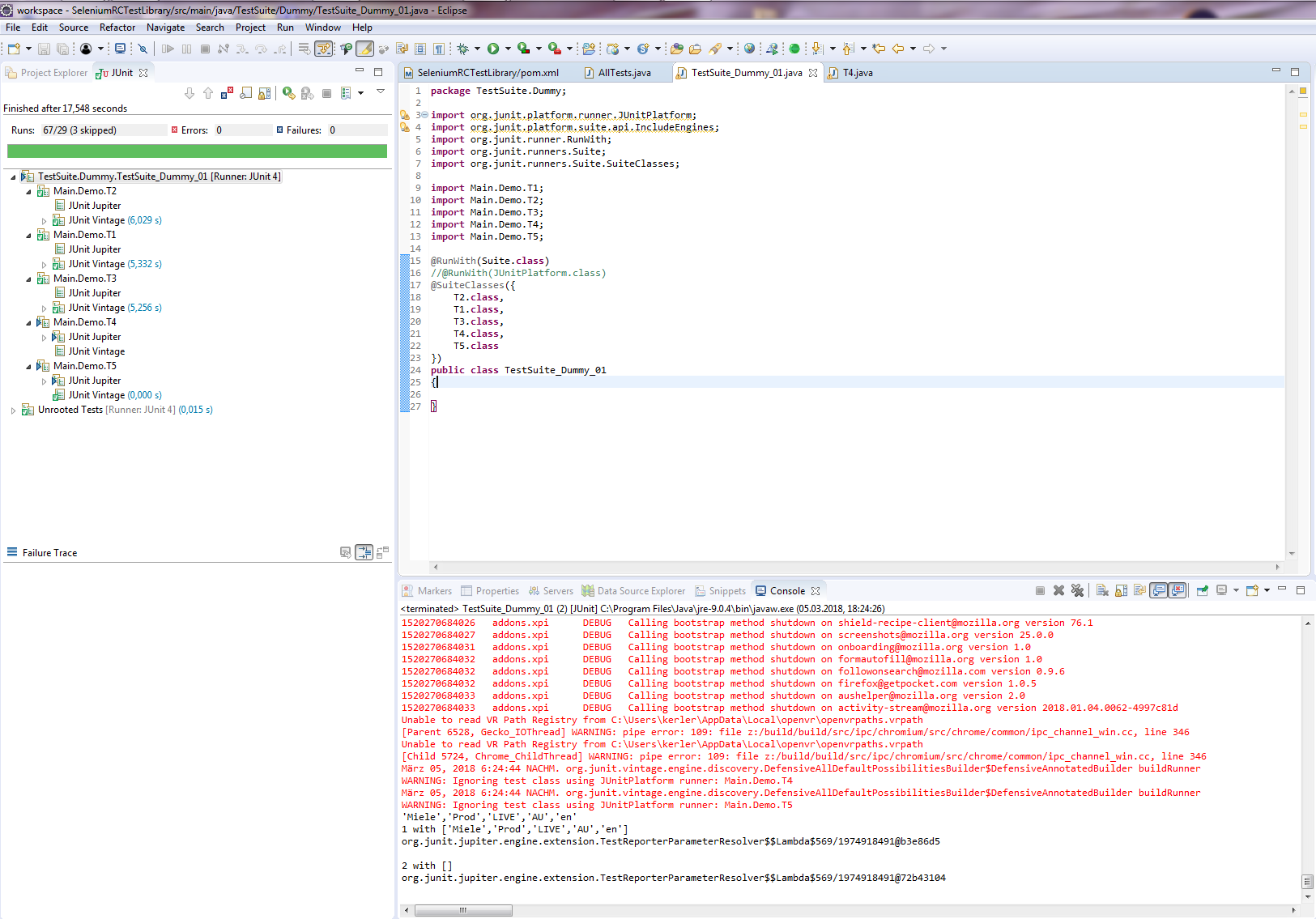
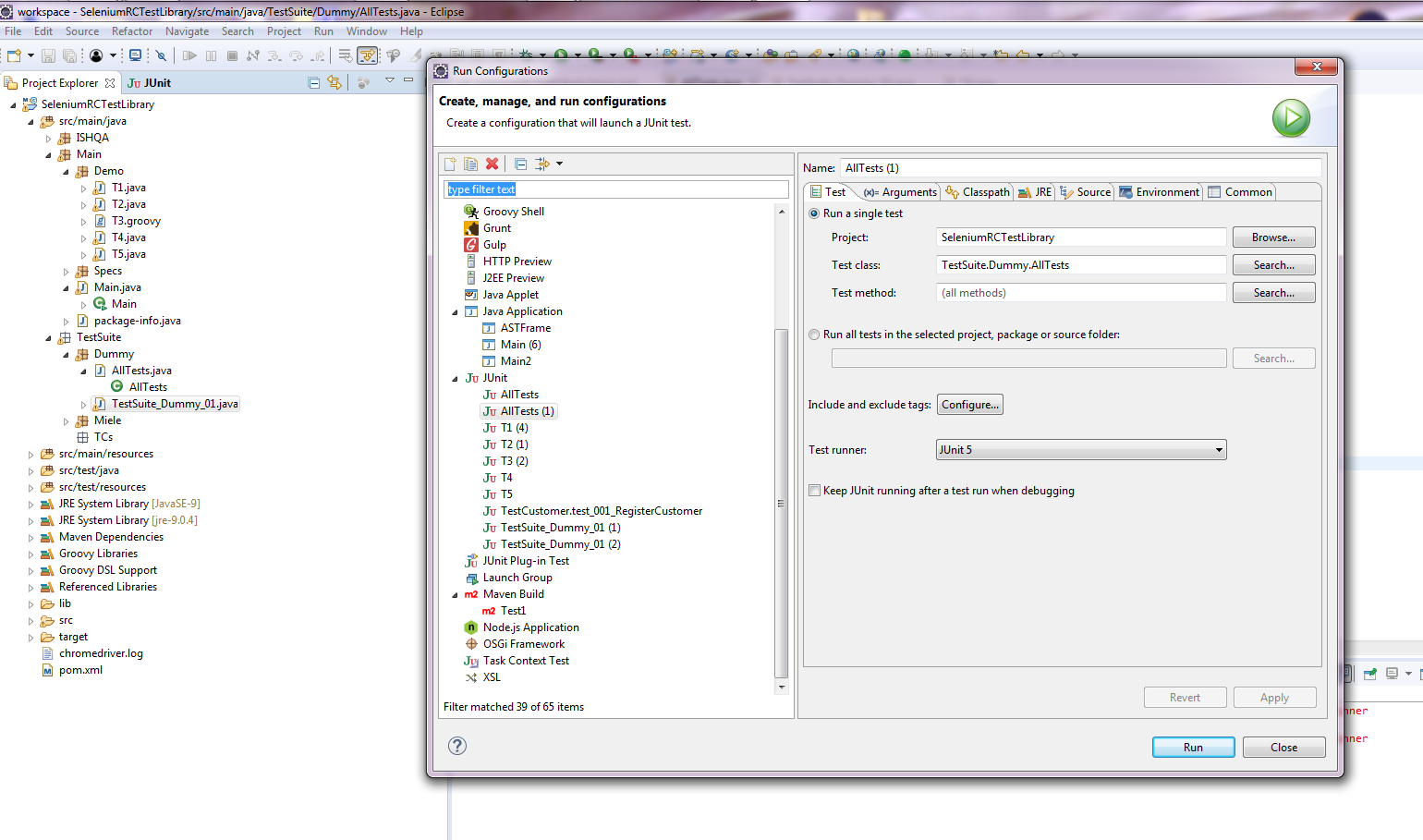
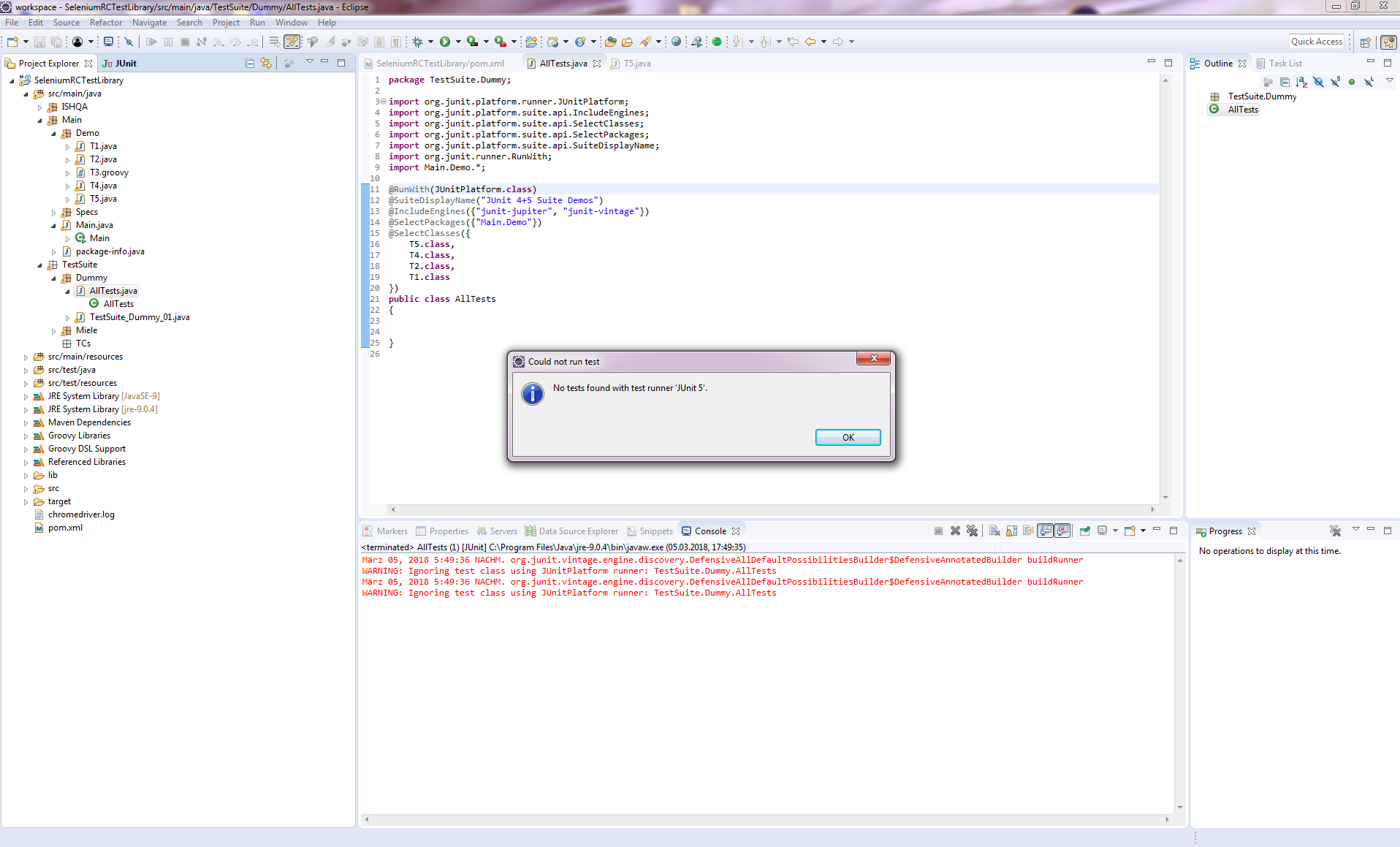
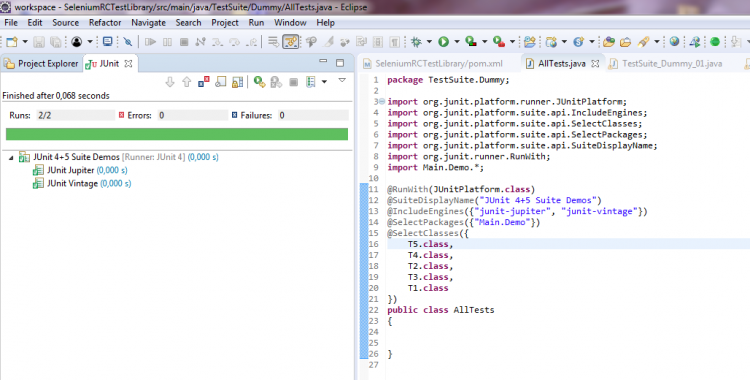
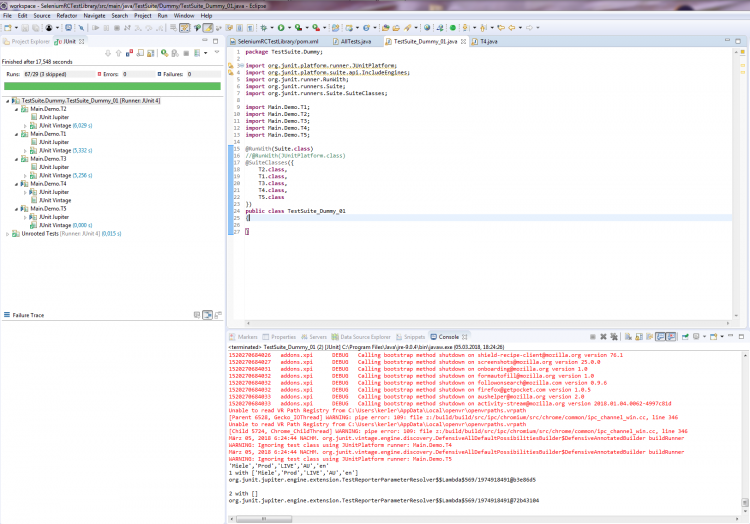
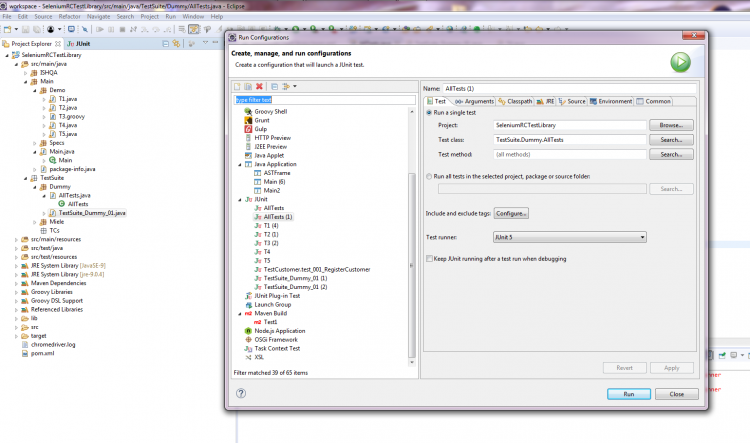
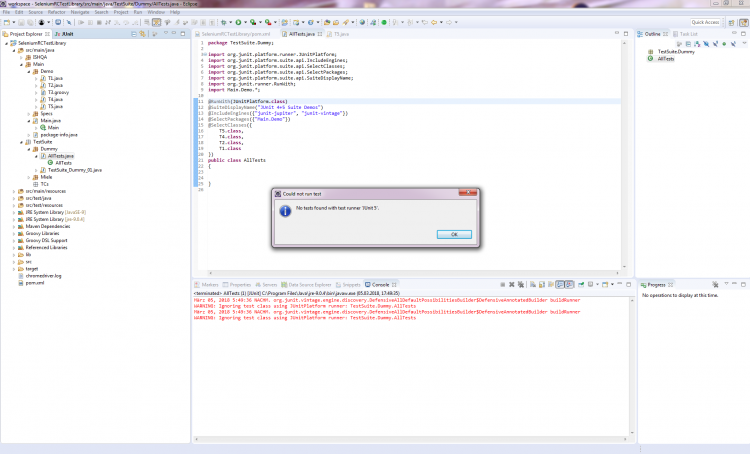
Hallo Zusammen, ich habe eine Reihe von jUnit 4-Tests (@RunWith(JUnitPlatform.class)) und neuerdings u.a. auch erste einfache jUnit 5-Tests. Einzeln lassen sich auch alle erfolgreich ausführen. Nun möchte ich mir gerne aus meinen Testklassen einzelne Test Suiten zusammenstellen: Hierzu eine jUnit 5-Test-Suite (die aber auch die bisherigen jUnit 4-Testklassen ausführen können sollte): package TestSuite.Dummy; import org.junit.platform.runner.JUnitPlatform; import org.junit.platform.suite.api.IncludeEngines; import org.junit.platform.suite.api.SelectClasses; import org.junit.platform.suite.api.SelectPackages; import org.junit.platform.suite.api.SuiteDisplayName; import org.junit.runner.RunWith; import Main.Demo.*; @RunWith(JUnitPlatform.class) @SuiteDisplayName("JUnit 4+5 Suite Demos") @IncludeEngines({"junit-jupiter", "junit-vintage"}) @SelectPackages({"Main.Demo"}) @SelectClasses({ T5.class, T4.class, T2.class, T3.class, T1.class }) public class AllTests { } Hierzu eine jUnit 4-TestSuite (die auch jUnit 5-Tests ausführen können sollte): package TestSuite.Dummy; import org.junit.platform.runner.JUnitPlatform; import org.junit.runner.RunWith; import org.junit.runners.Suite; import org.junit.runners.Suite.SuiteClasses; import Main.Demo.T1; import Main.Demo.T2; import Main.Demo.T3; import Main.Demo.T4; import Main.Demo.T5; @RunWith(Suite.class) //@RunWith(JUnitPlatform.class) @SuiteClasses({ T2.class, T1.class, T3.class, T4.class, T5.class }) public class TestSuite_Dummy_01 { } Problem ist nun, dass ich mit meinem Eclipse 4.7.2 (Oxygen.2 mit Java 9.0.4 und jUnit 5) es einfach nicht hinkriege, dass die jUnit 5-Tests im jUnit 5-Modus (Eclipse: Rechtsklick > Run As > RunConfigurations... > Test runner: JUnit 5) ausgeführt werden: Weder die obige jUnit 5-TestSuite als auch die untere jUnit 4-TestSuite führen unter Angabe des JUnitPlatform.class-Runners (im Quellcode die Annotation @RunWith) über die TestSuite keine Tests aus. Die jUnit 5-TestSuite findet laut Fehlermeldung "keine jUnit 5-Tests" (T4, T5) und auch die vorhandenen jUnit 4-Tests (T1, T2, T3) werden nicht mit ausgeführt: Das gleiche Verhalten zeigt sich auch bei der jUnit 4-TestSuite, wenn ich via @RunWith-Annotation den JUnitPlatform.class angebe (anstatt den Suite.class-Runner). Erst, wenn ich den jUnit 4-Modus (Eclipse: Rechtsklick > Run As > RunConfigurations... > Test runner: JUnit 4) einstelle und den Suite.class-Runner im Quelltext verwende, führt zumindest die jUnit 4-TestSuite sowohl die jUnit 4- als auch die jUnit 5-Testklassen aus: Bei der jUnit 5-TestSuite regt sich hingegen nichts bzw. er führt zwar den Test Run der TestSuite aus, aber keinerlei jUnit 4- und 5-Tests: Nun zu meinen Fragen/Problemen, wo ich Euch um Rat / Hilfe oder gar Lösungsvorschläge bitten möchte, da ich hier leider nicht weiter weiß: 1.) Es muss doch möglich sein, alles - jedoch insb. jUnit 5-Tests - im jUnit 5-Modus (Eclipse: Rechtsklick > Run As > RunConfigurations... > Test runner: JUnit 5) ausführen zu lassen? Für jUnit 4-Tests kommt schließlich junit-vintage und JUnitPlatform.class-Runner zum Einsatz, ansonsten jUnit Jupiter für die 5er. Was mache ich falsch? Im Internet finde ich leider nichts passendes. Gerne möchte ich von den jUnit 4-TestSuites weg. Aktuell scheint diese jedoch die einzige zu sein, die alles korrekt ausführt, wenn ich im jUnit 4-Modus ausführen lasse. Aber wie gesagt, mein Ziel sollen reine jUnit 5-TestSuites mit dem JUnitPlatform.class-Runner und den neuen Annotationen (@SuiteDisplayName, @IncludeEngines, @SelectPackages, @SelectClasses) wie oben zu sehen sein und nicht die alten jUnit 4-TestSuites. Ebenso möchte ich alle meine jUnit 4-Testklassen zu jUnit 5 migrieren. Aus meiner Sicht machen dann Runs im jUnit 4-Modus einfach keinen Sinn mehr. 2.) Gemeinsame Daten zwischen den Testklassen: Aktuell missbrauche ich aufgrund der nicht funktionierenden TestSuiten klassische jUnit 5-Tests als TestSuite-Container, mit deren Hilfe ich die anderen Testklassen bzw. der darin befindlichen Test-Funktionen ausführen lasse. Konkret geht es um SeleniumRC-Tests. Hierzu habe ich eine eigene Klasse geschrieben, die mir meine komplette Testumgebung erstellt, inkl. erzeugen des WebDrivers. Bisher musste ich in jeder Testklasse ein eigenes Objekt (QAE) dieser Klasse erzeugen lassen. Dadurch kann ich zwar Browsertests erfolgreich ausführen, die jedoch voneinander unabhängig laufen, weil jede Testklasse ein eigenes QAE-Objekt instanziiert. Strukturell ist meine Testklassen-Hierarchie jedoch so nicht gedacht und auch möchte ich nicht immer für jeden zu testenden Use Case alle möglichen Testfunktionen aus einer Testklasse ausführen lassen (z.B. für einen Checkout-Test - Testklasse: Bestellung - im eingeloggten Zustand, ohne die MyAccount-Seiten - zugehörig zu meiner Testklasse: Login - mit testen zu müssen). Gibt es Möglichkeiten, dass sich mehrere Testklassen bei jedem Run ein gemeinsames (QAE)-Objekt teilen? Und ist es möglich, dass sich Testklassen einander Daten austauschen (kommunizieren) können? Wenn ja (jeweils), wie? 3.) Interaktions- und / oder Steuerungsmöglichkeiten in TestSuites: Kann man bei klassischen TestSuites wie oben Daten / Objekte an die aufzurufenden Testklassen übergeben? Dies würde zumindest 2.) lösen, wenn die TestSuites denn funktionieren würden. Aber angenommen sie funktionieren irgendwann mal, wenn ja, wie kann ich in einer TestSuite Objekte an Testklassen überreichen? Und kann man auch steuernd in den Run einer TestSuite eingreifen? Bisher gebe ich in der Testsuite nur die Testklassen an, die nacheinander abgearbeitet werden sollen. Ich würde gerne bestimmte Testklassen und sogar einzelne Funktionen daraus vom weiteren Testrun JIT ausschließen wollen, wenn eine bestimmte vorhergehende Testklasse bzw. einzelne Testfunktion fehlschlug. Habt besten Dank schonmal im Voraus für Eure Hilfen. VG DITTY
-
Hallo Zusammen, ich bin derzeit dabei mich in jUnit 5 einzuarbeiten (mit Migrationsprojekten von jUnit 4 zu jUnit 5). Leider stoße ich derzeit an ein paar Grenzen meiner Kenntnisse. Konkret geht es um die nachfolgend genannten Dinge. Für Lösungen verwende ich u.a. diese Seite hier: https://howtoprogram.xyz/2016/10/28/junit-5-parameter-resolution-example/ (natürlich auch noch andere: z.B. https://junit.org/junit5/docs/current/user-guide/) Ich möchte gerne einfache Non-Parameterized- als auch Parameterized jUnit 5-Tests ausführen lassen, wo ich als Testfunktionsparameter jedoch keine Standarddatentypen (primitive, String, ENUMs, etc.) an die Testinstanzen übergebe, sondern Objekte eines eigenen Datentyps (ClientDescription). ClientDescription ist wie folgt definiert: package ISHQA.StdLibCore; public class ClientDescription { public String ...; public String ...; public String ...; public String ...; public String ...; public String ...; public String ...; public ClientDescription() { } public ClientDescription(String, String, String, String, String, String, String) { ... } } Hierzu habe ich für meine Klasse einen ParameterResolver (Parameter Resolution by type) geschrieben: package ISHQA.StdLibCore.jUnit; import org.junit.jupiter.api.extension.ExtensionContext; import org.junit.jupiter.api.extension.ParameterContext; import org.junit.jupiter.api.extension.ParameterResolutionException; import org.junit.jupiter.api.extension.ParameterResolver; import ISHQA.StdLibCore.ClientDescription; public class ClientDescriptionParameterResolver implements ParameterResolver { @Override public Object resolveParameter(ParameterContext parameterContext, ExtensionContext extensionContext) throws ParameterResolutionException { return new ClientDescription(); } @Override public boolean supportsParameter(ParameterContext parameterContext, ExtensionContext extensionContext) throws ParameterResolutionException { return (parameterContext.getParameter().getType() == ClientDescription.class); } } Damit funktioniert hier schonmal dieser nicht parametrisierte Test (test02(ClientDescription)): TestClass01.java: ================================================================== package Main.Demo; import ISHQA.StdLibCore.ClientDescription; import ISHQA.StdLibCore.jUnit.*; @RunWith(JUnitPlatform.class) @TestInstance(TestInstance.Lifecycle.PER_CLASS) @ExtendWith(ClientDescriptionParameterResolver.class) @DisplayName("Test cases") public class TestClass01 { //... @Test public void test02(ClientDescription client) { //...client... } //... } Nun bräuchte ich Rat / Hilfe beim Implementieren für folgende weiteren Dinge: 1.) Ich möchte das obige Beispiel gerne auf die gleiche Weise für parametrisierte Tests ausführen lassen, analog zum Beispiel für Strings: TestClass01.java: ================================================================== //... @DisplayName("Test Case 01") @ParameterizedTest(name = "{index} with [{arguments}]") @ValueSource(strings = { "'EAH','Prod','LIVE','DE','de'" }) public void test01(String testData) throws Exception { //...using testData... } //... Ich möchte gerne bei @ValueSource Objekte meines eigenen Datentyps angeben wollen, die übergeben werden sollen. Nur wie ist die Notation hierfür? Strings und Zahlen sind mir klar (siehe Beispiel), aber wie bei Klassenobjekten??? Und muss die ClientDescriptionParameterResolver-Klasse dazu noch angepasst werden? 2.) Ich möchte gerne den ClientDescriptionParameterResolver dahingehend anpassen, dass er mit beiden Konstruktoren von ClientDescription zurecht kommt, also wahlweise beide ausführen kann. Aktuell führt der ClientDescriptionParameterResolver nur den Standardkonstruktor von "ClientDescription()" aus, sodass jeder Testrun stets ein neu instantiiertes Objekt erhält. Im Hintergrund habe ich eine hardcodierte "Datenbank" mit mehreren Objekten vom Typ ClientDescription, die ich gerne für einzelne Testruns übergeben möchte. Muss ich hierfür den ClientDescriptionParameterResolver entsprechend abändern? 3.) Nach der Dokumentation kann man Parameter nach Name, Typ (wie oben schon implementiert), Annotation oder Kombinationen von diesen resolven. Analog zur Implementierung "Parameter Resolution by type" habe ich noch eine für "Parameter Resolution by annotation" versucht umzusetzen: ClientDescriptionAnnotationParameterResolver.java: ================================================================== package ISHQA.StdLibCore.jUnit; import java.lang.annotation.Annotation; import org.junit.jupiter.api.extension.ExtensionContext; import org.junit.jupiter.api.extension.ParameterContext; import org.junit.jupiter.api.extension.ParameterResolutionException; import org.junit.jupiter.api.extension.ParameterResolver; import org.junit.platform.commons.util.ReflectionUtils; public class ClientDescriptionAnnotationParameterResolver implements ParameterResolver { @Override public Object resolveParameter(ParameterContext parameterContext, ExtensionContext extensionContext) throws ParameterResolutionException { return ReflectionUtils.newInstance(parameterContext.getParameter().getType()); } @Override public boolean supportsParameter(ParameterContext parameterContext, ExtensionContext extensionContext) throws ParameterResolutionException { return parameterContext.getParameter().isAnnotationPresent(ClientDescriptionParam.class); } } ClientDescriptionParam.java: ================================================================== package ISHQA.StdLibCore.jUnit; import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target; @Target({ElementType.PARAMETER, ElementType.METHOD, ElementType.TYPE}) @Retention(RetentionPolicy.RUNTIME) public @interface ClientDescriptionParam { } , sodass Folgendes dann möglich wird: TestClass02.java: ================================================================== package Main.Demo; import ISHQA.StdLibCore.ClientDescription; import ISHQA.StdLibCore.jUnit.*; @RunWith(JUnitPlatform.class) @TestInstance(TestInstance.Lifecycle.PER_CLASS) @ExtendWith(ClientDescriptionAnnotationParameterResolver.class) @DisplayName("Test cases") public class TestClass02 { //... @Test public void test03(@ClientDescriptionParam ClientDescription client) { //... } //... } oder bzgl. der Parameter in Kombination alle Möglichkeiten zusammen: TestClass03.java: ================================================================== package Main.Demo; import ISHQA.StdLibCore.ClientDescription; import ISHQA.StdLibCore.jUnit.*; @RunWith(JUnitPlatform.class) @TestInstance(TestInstance.Lifecycle.PER_CLASS) @ExtendWith(ClientDescriptionParameterResolver.class) @DisplayName("Test cases") public class TestClass03 { //... @Test public void test02(ClientDescription client) { } @Test public void test03(@ClientDescriptionParam ClientDescription client) { } @ClientDescriptionParam @Test public void test04(ClientDescription client) { } @ClientDescriptionParam @Test public void test05(@ClientDescriptionParam ClientDescription client) { } //... } Auch hier analog zu 1.) und 2.) die Frage, was ich wo und wie anpassen muss, damit a.) meine eigene Annotation "@ClientDescriptionParam" auch bei @ParameterizedTest-Tests verwendbar wird, nicht nur bei @Test-Tests. Habt schonmal besten Dank im Voraus für Eure Hilfen. VG DITTY