KartoffelKiffer
-
Gesamte Inhalte
37 -
Benutzer seit
-
Letzter Besuch
Inhaltstyp
Profile
Forum
Downloads
Kalender
Blogs
Shop
Alle Inhalte von KartoffelKiffer
-
Hallo, seit einiger Zeit versuchen wir schon, die Embedded Variante von Windows auf unsere Industrie-Rechner zu bringen. Jedoch scheitern wir an der Flut von Möglichkeiten, die es mit dem Target Designer zu bewältigen gilt. Gibt es nun im deutschen Raum eine Möglichkeit, sich diesbezüglich schulen zu lassen? Leider finde ich recht wenig hierzu im Internet, weshalb ich mich an die Kollegen wende. Anders herum gefragt: Wie haben die unter euch, die selber schon einen PC mit Windows Embedded aufgesetzt haben, sich das Know-How angeeignet? Gruß, KK
-
MySQL-Connect mittels Connection Pooling
KartoffelKiffer antwortete auf KartoffelKiffer's Thema in Java
Hallo, Weil ich dann immernoch nicht weiß, wie der ganze Kram vernünftig funktioniert Da kann ich mich selbst zitieren und die Frage beantworten Ich hoffe nun mit c3p0 besser zu fahren, als zuvor. Es macht augenscheinlich ( nicht ausgiebig getestet ) einen sehr sehr vernünftigen Eindruck. Bislang keine Exceptions. Und auch die Performance lässt einiges offen.... Ich bedanke mich bei euch! MFG KK -
MySQL-Connect mittels Connection Pooling
KartoffelKiffer antwortete auf KartoffelKiffer's Thema in Java
Hallo, ich bin nun wiefolgt wiederfahren: private static ComboPooledDataSource ds = null; private static Connection con = null; private static boolean db_connected = false; public static void connect() { if (isConnected()) { System.out.println("is connected"); return; } else { System.out.println("is not connected"); } try { ds = new ComboPooledDataSource(); ds.setDriverClass("org.gjt.mm.mysql.Driver"); ds.setJdbcUrl(ReadConfig.Element("database_connectionstring")); ds.setUser(ReadConfig.Element("database_user")); ds.setPassword(ReadConfig.Element("database_pass")); con = ds.getConnection(); db_connected = true; } catch (Exception e) { System.out.println(e.toString()); db_connected = false; } } public static void distroyConnection() { try { DataSources.destroy(ds); db_connected = false; } catch (Exception e) { System.out.println(e.toString()); } } public static ResultSet executeQuery(String sql) { try { System.out.println("users: " + ds.getNumUserPools()); System.out.println("cons: " + ds.getNumConnections()); } catch (SQLException e1) { // TODO Auto-generated catch block e1.printStackTrace(); } try { return con.createStatement().executeQuery(sql); } catch (SQLException e) { try { connect(); return con.createStatement().executeQuery(sql); } catch (Exception e2) { System.out.println(e2.toString()); return null; } } } public static boolean isConnected() { try { ds.getConnection(); db_connected = true; } catch (Exception e) { db_connected = false; } return db_connected; } Ich führe also nun bei jeder Abfrage an die Datenbank meine Funktion executeQuery auf, die jedesmal ein Statement erstellt und ein ResultSet zurück gibt. Komisch ist nur, dass "System.out.println("cons: " + ds.getNumConnections());" bei einem Client 3 zurück gibt und bei einem zweiten 6. Wobei 6 Connections auch das Maximum sind. Kommt ein dritter Client hinzu, bleibt es bei 6 aktiven Connections. Eine Connection wird nie geschlossen bei mir, da die Applikation dauerhaft in einem Tomcat läuft. Die Funktion distroyConnection wird also nie aufgerufen. Sobald ich ein Statement bloß einmal erstelle (bsp) ds = new ComboPooledDataSource(); ds.setDriverClass("org.gjt.mm.mysql.Driver"); ds.setJdbcUrl(ReadConfig.Element("database_connectionstring")); ds.setUser(ReadConfig.Element("database_user")); ds.setPassword(ReadConfig.Element("database_pass")); stmnt = ds.getConnection().createStatement(); db_connected = true; kann ich auch bloß eine Abfrage gleichzeitig an die Datenbank senden. Überlappen sich zwei Abfragen (durch zwei gleichzeitig agierende Clients), so bekomme ich die Exception "Operation not allowed after ResultSet closed". Also generiere ich für jede Abfrage ein neues Statement und bekomme ein neues ResultSet zurück. Gibt es hierzu noch Anregungen/Anmerkungen oder Fragen? MFG KK -
MySQL-Connect mittels Connection Pooling
KartoffelKiffer antwortete auf KartoffelKiffer's Thema in Java
Hallo ihr zwei, ich habe das Ganze nochmals grundlegend überarbeitet und setze jetzt auf c3p0. Ebenfalls ist mir der (wirklich dumme....) Denkfehler sauer aufgestoßen, sodass ich diesen ebenfalls bereinige. Jetzt stellt sich mir noch eine weitere Frage: Ist es sinnig, in jeder Funktion, die auf die Connection zugreift - also jedesmal, wenn ich eine Abfrage an die Datenbank sende - ein Statement stmnt = new Connect.getConnection(); ResultSet rs = stmnt.createStatement(); rs.executeQuery("SELE..."); zu machen, wobei getConnection nun die Connection von ComboPooledDataSource zurück gibt?! Oder würde es Sinn machen, in einer Datenbank-Klasse eine Funktion executeQuery(queryString) zu erstellen, die auf dasselbe Statement-Objekt zurück greift und entsprechend nur jedesmal ein return rs.executeQuery(sql); zurück gibt? MFG KK -
MySQL-Connect mittels Connection Pooling
KartoffelKiffer antwortete auf KartoffelKiffer's Thema in Java
Hallo kingofbrain, Also würdest du sagen, dass die Funktion getConnection besser ds.getPooledConnection() zurück gibt, als ds.getPooledConnection().getConnection()? (pc wird erstellt mit ds.getPooledConnection(), also im Prinzip pc.getConnection()) Das Projekt C3P0 war mir bislang nicht geläufig. Hätte ich dadruch denn weitere Vorteile, die mir bei meinem jetzigen Problem fehlen? MFG KK -
Hallo, ich habe eine grundlegende Frage zur Arbeit mit Java und MySQL. Ich habe eine Klasse Connect, die folgendes Grundgerüst aufzeigt: pc = null; MysqlConnectionPoolDataSource ds = new MysqlConnectionPoolDataSource(); try { // Connection ds.setUrl(ReadConfig.Element("database_connectionstring")); ds.setUser(ReadConfig.Element("database_user")); ds.setPassword(ReadConfig.Element("database_pass")); // Reconnect ds.setAutoReconnect(true); ds.setAutoReconnectForConnectionPools(true); ds.setAutoReconnectForPools(true); pc = ds.getPooledConnection(); } catch (SQLException e) { new Exception(e.toString()); } Und eine weitere Funktion getConnection, die die Member-Variable pc zurück gibt. try { return pc.getConnection(); } catch (Exception e) { connect(); try { return pc.getConnection(); } catch (Exception ex) { new Exception(e.toString()); return null; } } Sobald ich eine Abfrage an die Datenbank stellen möchte, sieht der Ablauf folgendermaßen aus: Connection con = Connect.getConnection(); this.stmnt = con.createStatement(); ResultSet rs = this.stmnt.executeQuery("SELECT hose FROM kleidung WHERE name='Fritz'"); while(rs.next()) { (...) } Wenn ich also eine Abfrage absende, erstelle ich jedesmal ein neues ResultSet, das auf (in diesem Falle) this.stmnt zurück greift. Nun habe ich - wenn ich mehrere Abfragen in der Sekunde absende - einen Engpass, der sich folgendermaßen äußert: Manchmal kommt auch folgendes Szenario zustande: Jetzt frage ich mich, wie ich bei vielleicht 30-40 Abfragen (SELECT-Abfragen, alle WHEREs, GROUPs und ORDERs sind vernünftig indiziert) in der Sekunde so einen Engpass bekomme. Es handelt sich dabei um Abfragen über zwei Tabellen. Die eine zählt knapp 3.000 Einträge (wobei zwei Spalten ausgelesen werden) und eine weitere zählt knapp 5.000 Einträge, wo lediglich eine Bedingung auf eine Spalte der Tabelle besteht. Gehe ich die Abfrage nun generell falsch an oder wo kann dort mein Engpass liegen? Das grundlegende Problem dabei ist, dass ich nach Erhalt der Exceptions keine weiteren Abfragen mehr an die Datenbank senden kann. Erst., wenn ich den MySQL-Dienst neustarte, ist dies wieder möglich. Ich hoffe mir kann jemand helfen, auch gerne mit etwas guter Lektüre im Internet. Ich weiß nämlich nicht mehr, was ich noch weiter machen soll/kann. MFG KK
-
Hallo Martin, am Liebsten natürlich proprietär. LG KK
-
Hallo, mich erhaschte soeben folgendes Problem mit einer nüchternern Härte. Und zwar habe ich eine Software fertiggestellt, die folgende Komponenten benutzt: Apache Tomcat Apache HTTP NSIS (Nullsoft Installer - Stichwort Winamp) MySQL Eclipse Also folgende Lizenzen kommen zusammen: GPL (MySQL), EPL (Eclipse), Apache License (Apache-Produkte), zlib (NSIS). Dabei verwende ich eine Report-Engine von Eclipse, die einen Webserver (Apache) und einen Servlet-Container (Tomcat) benötigt, die wiederum auf MySQL zugreift. Alles zusammen ist in einem Installer verpackt, der mittels NSIS kompiliert wurde. Beim Installieren starte ich mittels msiexec den Installer von Apache und MySQL und installiere vollautomatisch in ein von mir vorgegebenes Verzeichnis. Die Installer von MySQL und Apache liefere ich also direkt im Installationspaket mit. Jetzt meine Frage (sehr nüchtern gestellt): Darf ich das Produkt so verkaufen? Stutzig macht es mich, dass MySQL einem dualen Lizenzsystem unterliegt, welches entweder properitär oder unter GPL steht. Muss ich hierzu Lizenzen von MySQL kaufen, da ich es im im Hintergrund recht simpel als Datenbank nutze? Ich connecte dabei über JDBC und ggf. über ODBC. Ich manipuliere keine Sourcen, verwende sämtliche Software lediglich als solche. Ich hoffe mir kann geholfen werden, mein Herz rast nämlich ein wenig. So wäre entsprechend einiges an Arbeit - wenn ich MySQL-Lizenzen kaufen muss - für die Katz, da sich das Prodult ggf. nicht mehr verkaufen ließe. LG KK
-
Hallo, die Crypto++ Bibliothek ist ja enorm. Ich wage schon fast den Vergleich zwischen Ameisen und Atombomben. Wie erwähnt brauche ich bloß eine Chiffrierung, die mittels Schlüssel eine Zeichenkette verschlüsselt. Der Gegenpart hat den Schlüssel ebenfalls und kann die Zeichenkette wieder entschlüsseln. Ich finde mich bisher im Chiffrierung-Dschungel nicht so zurecht, wie ich mir das gedacht hatte. Irgendwie wirkt alles für meinen Anwendungsfall zu oversized. Vielleicht hast jemand noch etwas Geduld mit mir und hilft mir ein wenig. // Edit: Ich habe vergessen zu sagen, dass ich eine fixe Schlüssellänge von 6 Zeichen habe. Somit fällt leider auch das Beispiel "A C++ Implementation of the Rijndael Encryption/Decryption method" ins Wasser. LG KK
-
Hallo, ich suche und suche, werde aber einfach nicht fündig. Und zwar benötige ich eine simple Klasse, der ein Schlüssel und ein Dateiname übergeben wird, und entsprechend eines mir irrelevanten Verschlüsselungsverfahrens, diese Datei anhand des Schlüssels verschlüsselt. Dabei sollte der Inhalt in keiner menschlich lesbaren Form vorliegen, sodass der Eindruck erst garnicht entsteht, die Datei zu entschlüsseln. Logischerweise sollte die Datei auch wieder entschlüsselbar sein. Und das auch nur mit exakt demselben Schlüssel, wie er auch zur Verschlüsselung verwendet wurde. Leider bin ich im Internet nicht so fündig geworden, wie ich mir das erhofft hatte. Und so etwas selber zu schreiben, finde ich unnötig verschenkte Zeit. Ich bin sicher, es gab vor mir schon jemanden, der ein ähnliches Problem hatte. Nur leider obliegt mir dieser jene welcher nicht. Ich hoffe mir kann geholfen werden und es hat jemand einen Link oder ein Beispiel parat. Mit freundlichen Grüßen, KK
-
Hallo, kennt jemand von Euch eine Möglichkeit, um einen MySQL-Server in der Version 5.0.67 von Hand zu zerschießen, sodass ein REPAIR TABLE von Nöten ist, um die Tabellen wieder zu reparieren? Oder auch anders gefragt, welche Ursachen kann es haben, dass sich eine MyISAM-Tabelle zerschießt? Mfg Tom
-
Absturz des Rechners bei Anschluss von USB-Geräten
KartoffelKiffer antwortete auf KartoffelKiffer's Thema in Hardware
Hallo, mit einem Ubuntu Live-System habe ich getestet, ob der Rechner ebenfalls bei USB-Produkten abstürzt. Das war nicht der Fall. Ich konnte also davon ausgehen, dass es kein elektrisches Problem gibt und der Fehler auf Windows-Ebene zu suchen ist. Wie Du schon geschrieben hast, habe ich die Treiber einmal neu installiert, so auch den des USB Host-Controllers. Und siehe da - das Problem ist gelöst. Es hat sich also tatsächlich der USB-Treiber zerschossen. Warum auch immer. Ich bedanke mich für die zahlreiche Hilfe und Tipps. Mfg Tom -
Absturz des Rechners bei Anschluss von USB-Geräten
KartoffelKiffer antwortete auf KartoffelKiffer's Thema in Hardware
Es ist ein Fehler der Kategorie "PAGE_FAULT_IN_NONPAGED_AREA". Dazu habe ich folgende Seite gefunden. Mittlerweile zweifel ich daran, ob es sich wirklich um eine Art Spannungsspitze handelt, die den Rechner zum herunterfahren zwingt. Jedoch bin ich mit meinem Latein langsam am Ende. Was wäre denn noch zu machen? Mfg Tom -
Absturz des Rechners bei Anschluss von USB-Geräten
KartoffelKiffer antwortete auf KartoffelKiffer's Thema in Hardware
Hallo, ja es tritt ein Bluescreen auf, der den Rechner zum Stillstand bringt. Habe schon versucht den Treiber über die beigelegte CD zu installieren, doch die Installation wünscht das Einstecken des W-LAN Sticks. Das gelingt nicht, da wieder der Bluescreen auftritt. Wenn ich meinen USB-Stick einstecke, so tritt ebenfalls der Bluescreen auf. Die Bootreihenfolge impliziert keinerlei USB-Devices. Würde ein USB-Hub da Abhilfe verschaffen? Leider bin ich mir nicht sicher, ob der Bluescreen auch auftritt, wenn der USB-Port eine Spannungsspitze erzeugt, die den Rechner neustarten lässt (meine anfängliche Vermutung, die aber durch den Bluescreen ins Zweifeln gerät). Mfg Tom -
Absturz des Rechners bei Anschluss von USB-Geräten
KartoffelKiffer antwortete auf KartoffelKiffer's Thema in Hardware
Hallo, die Tatsache, dass der Anschluss des Handys über USB zur Datenübertragung funktioniert, lässt mich darauf schließen, dass es sich um ein elektronisches Problem handeln könnte. Jetzt habe ich bei reichelt ein wenig nach USB-Hubs mit externer Stromversorgnung geschaut. Zur Not müsste ein solches Gerät her halten. Ich werde heute Abend nochmal meinen USB-Stick versuchen, und zum anderen den W-LAN Stick in meinem Notebook testen. Wenn der W-LAN Stick bei mir läuft, und der USB-Stick keinen Absturz verursacht, würde ich den Weg suchen, den USB-Geräten über das externe Hub Strom zu geben. Ich halte Euch auf dem laufenden. Btw. taugt ein Gerät für 9,30 Euro aus dem reichelt-Shop wohl etwas? Mfg Tom -
Hallo, ich habe ein Problem mit dem Rechner eines Bekannten. Und zwar startet der Rechner beim Anschluss eines USB-Gerätes neu. Es existieren insgesamt 6 USB-Ports an dem Rechner, und bei jedem tritt dieser Fehler auf. Der Anschluss eines Handys über USB verläuft fehlerfrei. Erst ein W-LAN Stick oder ein W-LAN Modem bringen den Rechner zum Absturz. Hängt ein solches Gerät schon beim Start des Rechners an, so fährt dieser garnicht erst hoch. Er bootet beim Windows-Startdialog neu; endlos. Ein Abschalten der USB-Devices im Bios hat zur Folge, dass der Rechner zwar hochfährt, jedoch (logischerweise) die USB-Geräte nicht erkannt werden. Was mich jetzt natürlich stutzig macht ist, warum dieser Fehler bei jedem Port auftritt. Wenn mal einer defekt ist, würde ich das ja verstehen, aber alle zusammen erscheint mir sonderlich. Noch zusätzlich: Zwei der Ports sind direkt am Mainboard angebracht, weitere zwei sind als PCI-Karte integriert, die letzten zwei sind vorne am Gehäuse angebracht und sind über das Mainboard verbunden. Hat jemand eine Idee was das sein könnte? Und vor allem wie ich das Problem lösen kann? Mfg Tom
-
Ganz einfach, weil die Daten lokal immer verfügbar sein müssen, egal ob eine Netzwerkverbindung besteht, oder nicht. Wenn sie auf einen Master geschoben werden, der dezentral irgendwo im Netzwerk steht, dann muss stets eine Verbindung bestehen, sonst sieht man lokal die Daten erstmal nicht. Da würde vielleicht folgende Frage aufkommen: Wieso kann ich die Daten nicht lokal einsehen, wenn sie doch lokal produziert wurden? Die Antwort würde dann lauten: Weil wir die Daten erst einmal über das Netzwerk an eine Zentrale senden, damit sie lokal wieder repliziert werden können. Ich verstehe schon wie Du das meinst, das war auch mein erster Gedanke, aber versuch das mal logisch wem klar zu machen. Darum fahre ich auch nicht auf dieser Schine.
-
Hallo, mein Problem besteht immernoch. Darum spezifiziere ich etwas genauer. Es existieren mehrere Rechner, in die Daten stets lokal eingeschleust werden. Diese Rechner sollen ihre Daten auf eine zentrale MySQL-Datenbank replizieren. Ich weiß es gibt die Möglichkeit von auto_increment_increment und auto_increment_offset. Wenn ich also an jedem Rechner in der Datenbank einen auto_increment_offset von 1-n (Rechnernummer) setze und einen auto_increment_increment von 1000, so müsste das Problem der Foreign-Key Verwaltung gelöst sein. Ein Beispiel: Rechner 1: auto_increment_increment = 1000 auto_increment_offset = 1 ------------------------ Rechner 2: auto_increment_increment = 1000 auto_increment_offset = 2 Rechner 1 produziert also Daten 1, 1001, 2001, 3001 usw., Rechner 2 produziert 2, 1002, 2002 usw. Jetzt muss ich diese Daten nur noch in die Master-Datenbank bekommen. Mit dem Replikationsverfahren habe ich mich nun zu genüge auseinander gesetzt. Das Prinzip funktioniert so nicht. Ich MUSS die Daten lokal in den Rechner schreiben, und von der lokalen Datenbank ein Abbild auf dem Server erstellen. Das Replikationsverfahren allerdings verlangt ein Schreiben in den Server (Master) und das Replizieren auf die lokalen Rechner. Ich hoffe die ganze Geschichte ist jetzt etwas klarer und mir kann geholfen werden. // Edit: Im Prinzip benötige ich eine Replikation VON einem Slave-Server IN einen Master-Server. Also genau andersherum, wie es die Replikation unter MySQL vorsieht. Es gibt auch sogenannte Master-Master Replikationen, wo beide als Master und beide als Slave fungieren. Das funtioniert allerdings nur bei zwei Rechnern. Ich habe aber n Slave-Systeme und immer einen Master-Rechner. Mfg Tom
-
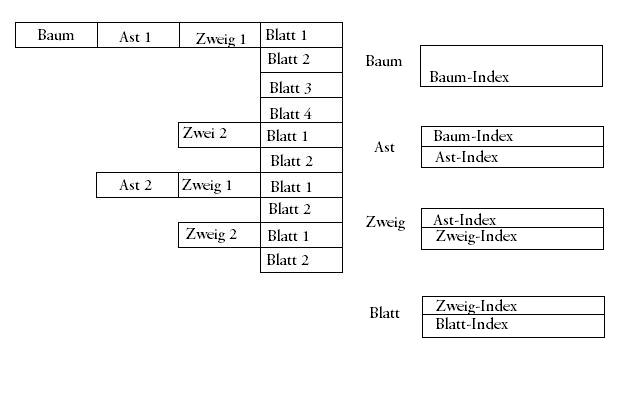
Hallo, es geht hier in diesem Beitrag um die Replikation mehrerer Slave-Systeme auf ein Master-System. Mein Problem beläuft sich auf die Indizierung meiner bestehenden Slave-Systeme. Im Anhang habe ich eine kleine Grafik anbei gefügt, die die Struktur einmal kurz zeigen soll. Prinzipiell kann man es so verstehen: Es existiert ein Baum, der mehrere Äste haben kann. Der wiederum kann mehrere Zweige haben, an dem wieder n Blätter hängen. Jede Tabelle ist mit der Elterntabelle verbunden. Ein Blatt hat also eine Zweig-ID, ein Zweig eine Ast-ID usw. Ist es mittels MySQL-Tools nun irgendwie möglich, eine automatische Replikation meiner Slave-Systeme auf ein Master-System zu vollziehen, die folgendes berücksichtigt: Die Slave-Systeme sind vom Aufbau her identisch, genau wie das Master-System auch. Sogar die Versionen von MySQL werden gepflegt. Habe ich nun im Slave-System 1 einen Baum mit der ID 123, so hat dieser einen Ast mit der ID 111 und einen mit ID 112 usw., besteht nun die große Warscheinlichkeit, dass im Slave-System 2 ebenfalls ein Baum mit der ID 123 besteht, nur vielleicht mit verschiedener Anzahl Äste, Zweige und Blätter. Nun steht in jedem Ast die ID des Baumes. Trage ich aus dem Slave-System 1 nun meine Äste in das Master-System ein, so bestehen Äste mit der Baum-ID 123 aus Slave-System 1 UND Slave-System 2. Die Baum-ID 123 lautet nun aber auch völlig anders. Die ID im Master-System wird per auto_increment automatisch um eins erhöht. Sie kann also für den Baum mit der ID "123" aus dem Slave-System 1 "87625" lauten, und aus dem Slave-System 2 "5". Es muss also dafür gesorgt werden, dass der Foreign-Key (die ID des Baumes) der Äste automatisch den Wert erhält, der dem neuen Baum in dem Master-System zugewiesen wurde. Auch die ID´s der Äste sind different als in dem Slave-System, also müssen auch die Zweige von den neuen ID´s benachrichtig werden, genauso wie die Blätter auch. Eine MySQL-Replikation muss also davon unterrichtet werden wie die Zusammenhänge der Datenbank aussieht. In meinem Fall doch recht einfach 1 zu n, da ein Baum n Äste haben kann, n Äste aber wiederum zu einem Baum gehören usw. Ich hoffe mein Problem ist klar dargestellt, und es gibt eine Lösung dafür. So speziell ist die Frage hoffe ich nicht, alsdass MySQL dafür keine Lösung hat. Mfg Tom
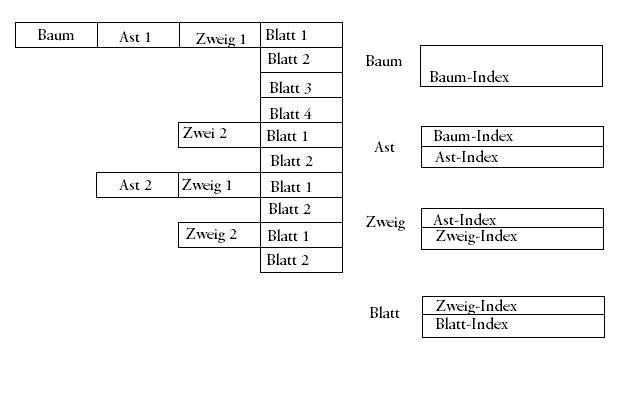
-
Hallo, ich nutze MySQL schon eine Weile, und bin auch sehr zufrieden damit. Jetzt geht es langsam ans Eingemachte, nämlich der MySQL und Indizierung von Spalten. Natürlich habe ich mich im Internet hinreichend informiert, nur bleiben einige Fragen dennoch offen. Ich stelle jetzt einfach mal eine Liste von Fragen auf, die mir im Kopf herumschwirren. 1.) Die größte Frage überhaupt: Wie speichert MySQL seine Indizierung ab? Wie ich gelesen habe, sind es Hashwerte, die zur eindeutigen Identifizierung dienen. 2.) Wie groß ist der Streuwert dieser Hashwerte? 3.) Frage 2 hat einen Hintergedanken. Und zwar geht es um die Funktion "LIKE". Indiziere ich eine Spalte "Mitteilung", welche vom Typ VARCHAR ist und 255 Zeichen lang sein kann und darauf einen Index lege. Kreiere ich nun eine Anweisung 'SELECT Mitteilung FROM Mitteilungen WHERE Mitteilung LIKE "Irgendein Text%"', greift dann die Indizierung dennoch? Wenn ich mir einen Hashwert vorstelle, der 32 Zeichen lang ist, der Streuwert dieser Hashfunktion nun enorm ist, sodass wenn ein Bit anders gesetzt ist, der komplette Hash völlig different zum Vorgänger aussieht, so kann ich mir einen Vergleich nicht vorstellen. Man nehme MD5. Ich speichere "Dies ist ein Test" in MD5 ab, heraus kommt "6cddeb6a2f0582c82dee9a38e3f035d7". Suche ich nun nach "Dies ist%", also einer Zeichenkette "Dies ist" und darauffolgendem Text, der irrelevant ist, so erhalte ich "1759ed07e43fad6f7077d52482750252". Also einem völlig anderen Ergebnis, welches schier nicht verglichen werden kann. 4.) Meine Vermutung lautet also, MySQL nutzt eigene, intelligente Hashfunktionen, die einen geringen Streuwert aufweisen, um so etwaige ähnliche, oder teilstring-behaftete Werte ausfindig zu machen (sofern ein Index auf ein Feld mittels LIKE überhaupt greift). 5.) In eine ähnliche Richtung geht auch meine folgene Frage: Was ist, wenn ich ein Datumsfeld indiziere. Und ich alle Datensätze älter als 01-01-2007 haben möchte, also < 01-01-2007. Greift da ebenfalls die Indizierung? Es würde von einer Eingabe ein Hash gebildet werden (01-01-2007) und mit einer Anzahl n aus der Datenbank verglichen werden. 6.) Global gesprochen: Greift ein Index bei Anweisungen, die nicht dem "="-Operator entsprechen (wie z.B. <, >, <>, LIKE etc.)? 7.) Wenn ich eine Abfrage habe, mit mehreren WHERE-Bedingungen. Wäre es sinnvoll für diese (vielleicht eine signifikante) Abfrage einen eigenen Index zu erstellen? Als Beispiel, ich möchte einen Datensatz mit einem bestimmten Wert und einem bestimmten Zeitraum ermittelt haben (WHERE Wert="abcdefg" AND Time < NOW()), wäre es klug einen Index anzulegen, über die Spalten "Wert" und "Time"? So würde doch explizit eine Indizierung über die beiden Spalten erfolgen, also auch explizit eine geringe (oder überhaupt nur eine) Menge ausgeben werden (die Menge, die dem Wert und dem Zeitraum entsprechen)? 8.) Ist es möglich tabellenübergreifend Indizes zu erstellen? Gesetz dem Fall, dass meine Behauptung, die in Punkt 7 gestellt wurde, wahr ist (also dass die Indizierung über mehrere Spalten für spezielle Abfragen Pluspunkte bringt), ich Indizes erstellen kann, die über Tabelle1.Spalte1, Tabelle1.Spalte2 und Tabelle2.Spalte1 gehen? Es tut mir leid, wenn das hier alles etwas viel erscheint. Aber das sind im Moment Punkte, die mir als Dorn im Auge erscheinen. Viel Text finde ich darüber leider nicht im Internet, weshalb ich noch etwas im Dunklen stehe. Ich hoffe es nimmt sich jemand meinen Fragen an. Mfg Tom
-
Hallo, ich bin mir wohl im Klaren darüber, was XML ist. Es ging mir auch nicht um das einzelne XML-Dokument an sich, sondern eher um das Gegenstück zu SQL aus dem Hause XML, XQuery. Habe mich vielleicht nicht ganz auf den Punkt gebracht ausgedrückt. Mfg Tom
-
Hallo, in letzter Zeit stellt sich mir immer häufiger die Frage: XML- oder SQL-Datenbank. Ich arbeite an einem größeren Projekt, seit etwa einem halben Jahr. Es wird auch noch ein wenig dauern, bis alles so in Serie gehen kann. Nur werde ich des letzteren immer häufiger mit XML-Datenbanken konfrontiert. Es kommt mir bald so vor, als bestünde jeder Datenfluss nur noch aus XML-Konnektivitäten. Wohin geht der Trend Eurer Meinung nach in den nächsten 5-10 Jahren? Stirbt SQL aus? Übernimmt XML die Oberhand? Entwickelt sich der Standard der W3C so erheblich, dass er SQL unter sich vergräbt? Da gräult es mir ein wenig vor, da ich mit SQL groß geworden bin. Gut, SQL besteht schon seit den 70ern und es wäre Zeit für etwas Neues. Aber XML ist doch auch kein neu erfundenes Rad oder täusche ich mich da? Es werden lediglich Standards entworfen, die es einheitlich regeln sollen, wie ein XML auszusehen hat - wie bei SQL. Ist SQL nach den 30 Jahren nun ausgereizt? Wird XML folgen? Es nimmt ähnliche Ausmaße an, wie SQL damals, also, warum nicht darüber nachdenken, ob es auch in Zukunft in ähnlichem Ausmaße wächst. Mfg Tom
-
Moin, seit wann ist es eigentlich möglich, aus der IP-Adresse die Region herauszufinden, aus der man kommt? Bereich 83.xx.xx... und Bereich 84.xx..... gehören zB zu Deutschland etc. Hier zum Nachschlagen. Verwirrt mich gerade etwas. Daher wissen die Leute, die die Werbung für die Kontaktanzeigen schalten, auch gleich, welche Girls mich ansprechen Mfg Tom
-
Hi, ich habe den PC gestern aufgeschraubt, es sind 2 USB-Steckplätze, die mit dem Mainboard verbunden sind. Es ist keine nachträglich installierte Karte. Wieso denn besteht auf der Fujitsu-CD/Seite kein Treiber für das Gerät? Es ist so, die beiden Steckplätze sind mit dem MB verbunden. An einem der Steckplätze steckt der WLAN-Empfänger von der T-Com Sinus 154 DataII. Dieser Empfänger von der T-Com leuchtet nicht einmal, sodass ich darauf schließen kann, dass er keinen Strom per USB bekommt. Somit auf ein Treiberproblem zu führen ist. Wird ja auch durch den Gerätemanager bestätigt. Eigentlich wollte ich eine andere XP-Version, die Professional von mir auf den Rechner spielen, mit SP2 und allem pipapo. Doch unter dieser Version von Windows trat das Problem auf, dass der Treiber nicht installiert werden konnte. Also hab ich die Recovery-CD von Fujitsu Siemens verwendet, auch ohne Erfolg. Es wurden alle Komponenten richtig installiert, bis auf den USB-Adapter. Ich hab den Rechner auch schon hier gehabt (steht bei meiner Freundin) und habe ihn hier an das LAN angeschlossen und versucht über das Internet Updates zu laden. Ohne Erfolg. Vor der Installation funktionierte der Steckplatz noch einwandfrei. Windows möchte allerdings NUR einen Treiber dafür haben, wenn auch ein Endgerät (in dem Falle das Sinus 154 DataII) angeschlossen ist. Wenn dies nicht der Fall ist, erkennt er den Adapter garnicht und mängelt auch nicht, dass kein Treiber dafür installiert ist. Mfg Tom
-
Hi, genau, ist ein XP-Home Rechner mit SP1. Habe davor aber auch schon ein Professionell mit SP2 auf dem Rechner gehabt. Ob andere Endgeräte funktionieren weiß ich nicht, dürfte denn jedes USB-Gerät an der Karte laufen? Welchen USB-Treiber meinst du? Es ist kein Treiber von dem Gerät installiert worden (das ist ja mein Problem). Und auf das Internet zugreifen kann ich auch nicht, da der WLAN-Empfänger (Sinus 154...) an genau dieser USB Adapter-Karte hängt und somit nicht läuft. Mfg Tom