Gateway_man
-
Gesamte Inhalte
1167 -
Benutzer seit
-
Letzter Besuch
Inhaltstyp
Profile
Forum
Downloads
Kalender
Blogs
Shop
Alle Inhalte von Gateway_man
-
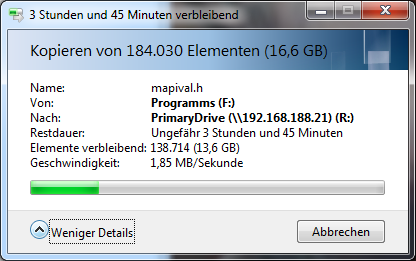
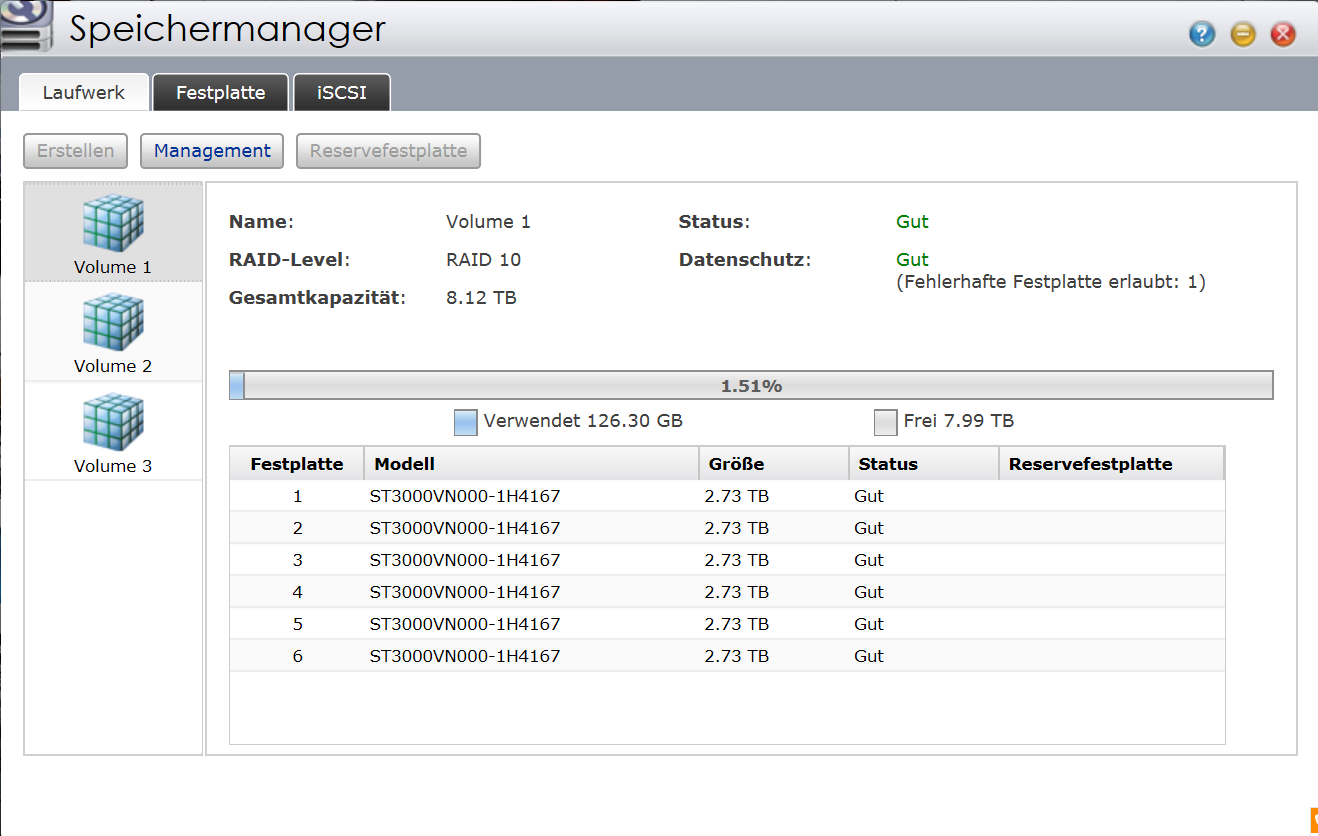
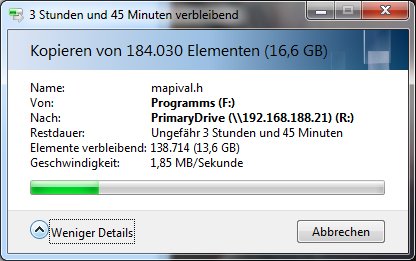
Hallo, nochmal ich. Ich hatte mir ein NAS und 24 TB (8x3TB 24/7 NAS Platten) gekauft (Hier bereits erklärt). Jetzt hab ich diverse Raid Konfigurationen durchgespielt und muss sagen ich bin mehr als schwer enttäuscht. Eine einzelne Platte erreicht einzeln (30MB schreibend, 55 MB lesend). Wenn ich das 6 Platten zu einem RAID10 konfiguriere bekomme ich beim schreiben von großen Dateien noch 20 MB/s. Bei vielen kleinen Dateien bin ich fast vom Stuhl gefallen. (Leider habe ich mehr kleine Dateien als große!) Das ist die Verbund-Konfiguration: Ich brauche also für Verschiebung meines "Source Code" Ordners 5 Stunden. Ich dachte RAID10 soll die Vorteile von 1 und 0 verbinden. Aber von Performance seh ich da überhaupt nichts. Spannend ist auch folgendes: Ich habe alle 8 Platten testweise mal zu nem RAID 0 zusammen geschlossen. Die Geschwindigkeiten von Lese -und Schreibvorgängen waren immernoch minimal geringer, als wenn ich eine Platte ohne Verbund verwende. Da das meine ersten Erfahrungen mit RAID sind muss ich sagen. Entweder stimmt hier was gewaltig nicht, oder RAID ist für keinen Anwendungszweck zu gebrauchen. Denn mit 1,85 MB/s kann man sicher nicht produktiv arbeiten. Ich überlege gerade ob ich die Platten per JBOD verbinde. Die Frage die ich hierzu habe ist, kann man auf die anderen Daten noch zugreifen, wenn eine Platte im Verbund ausfällt? Ich kenne mich da leider nicht so gut aus. Falls jemandem noch eine Konfiguration neben JBOD vorschlagen möchte bin ich gerne bereit das zu testen. Zur Verfügung stehen mir 8x3TB Platten und der Controller beherrscht die RAID Level 0, 1, 5, 6 und 10. Mir geht es hauptsächlich um Performance. Auf die NAS sollen später noch die Festplatten diverser virtueller Maschinen die auch von dort aus geladen werden sollen. LG Gateway
-
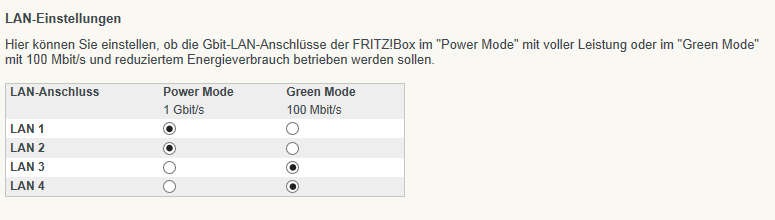
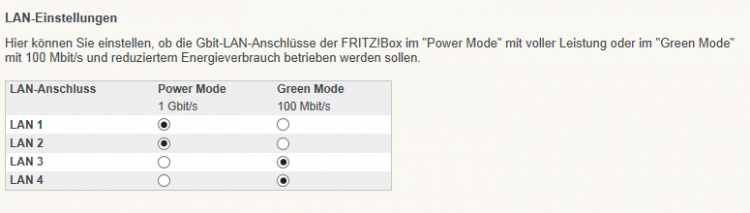
So an der Stelle muss ich mich bei euch Entschuldigen für mein Überhastet erstellten Thread. Stellt sich raus das, sobald man bei der Fritzbox ein Netzwerkkabel einsteckt, dieser Port im Green Mode läuft. Ihr könnt das in der Fritzbox ändern. Für mich noch unbegreiflich warum man das per Default so macht. So sieht das dann aus: LG & Danke Gateway
-
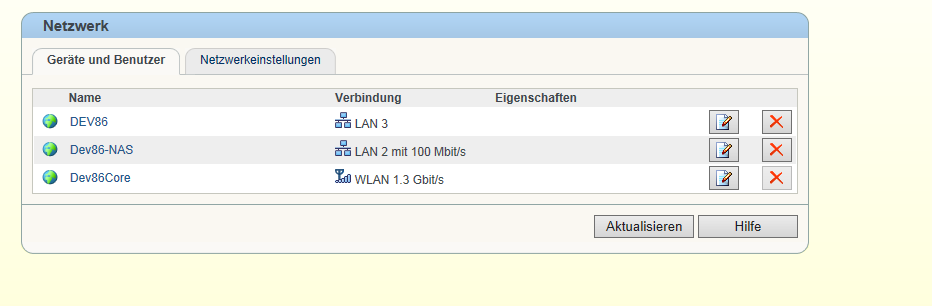
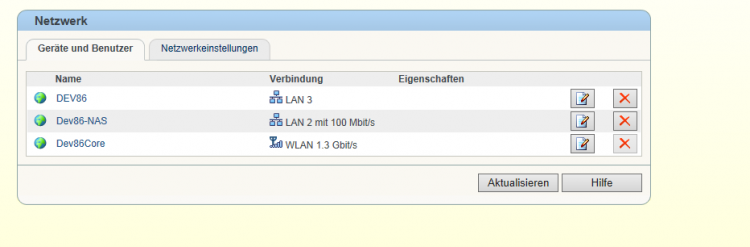
Hallo liebe Leute, ich hatte mir vor kurzem eine NAS gekauft (Asustor AS-608T (Datenblatt)). Zudem hab ich mir die Fritzbox 7490 (Datenblatt) gekauft (hauptsächlich wegen Gigabit W-LAN). Soweit alles verkabelt und eingerichtet. Das Gigabit-WLAN funktioniert hervorragend. Sogar schneller als das Gigabit LAN . Die Ernüchterung kam als ich Daten auf die NAS speichern wollte. Ich erreiche maximal 12 MB/s. Das Problem wurde schnell identifziert. Die Fritzbox zeigt mir an das LAN2 Anschluss (da hängt die NAS dran) mit 100Mbit angebunden ist. Der Verbindungskabel zwischen Fritzbox und NAS ist ein CAT5e. Komplette Beschriftung auf dem Netzwerkkabel sieht wie folgt aus: "UTP CABLE 24AWG 4PR (UL) E324441 ETL VERIFIED TIA / EAI-568B.2 CAT5e PATCH CABLE 100 MHz" Ich hatte Ursprünglich das Netzwerkkabel in Vermutung, bin mir da aber auch nicht mehr so sicher und habe gegenwärtig kein anderes zur Verfügung stehen. Fällt euch außer dem Kabel noch etwas anderes ein/auf? LG & Danke Gateway
-
Sehr gute Frage . Das war Default so drin. Hab in dem Bios Untermenü noch nie rumgefummelt. Wie gesagt. Bin verwundert das es bisher so tadellos funktioniert hat....
-
Abend, bin total happy . Funktioniert. Sogar mit dem USB Laufwerk. Hatte heute noch mit nem Kollegen gequatscht und der meinte das er für seine SSD zwangsläufig AHCI aktivieren musste, sonst konnte er nicht von ihr Booten. Da ich bereits eine SSD im Einsatz habe (auch als System Partition) nahm ich an das ich das bei mir auch aktiviert hatte. Wie ich mich da geirrt hatte. Ich habs dann bei bei "OnChip SATA Type" und bei "Onboard SATA/IDE Ctrl Mode" auf AHCI gestellt. Windows neuinstalliert und alles wunderbar . Seltsam find ich es dennoch das meine alte SSD ohne Probleme lief. LG & Danke Crash2001 Gateway
-
Hi. Das klingt tatsächlich sehr logisch. Ich hab noch ein DVD Laufwerk lose in der Ecke liegen. Das könnte ich für die Installation ja mal fix einbaun (sofern das noch funktionstüchtig ist). Ich glaube das werd ich als aller erstes machen, da es sich wirklich sehr logisch anhört. Vielen Dank für deine Hilfe. Werde morgen mal ne Rückmeldung geben. LG Gateway
-
Hi Crash2001, danke für deine Tipps. Ich werde das heute Abend mal ausprobieren. Vermutlich schon. Es laufen ja bereits mehrere S-ATA Platten erfolgreich. Werde ich prüfen. Muss mal schaun wie das bei meinem MB Bios geht. Wie kann ich das prüfen? Glaube aber das bei der Installation von Windows Primär und nicht Logisch dran stand. Ansonsten müsste das ja in der Datenträgerverwaltung nachprüfbar sein oder? Hm da weiß ich nicht wie ich das nachprüfe. Werd dazu mal google befragen. Das weiß ich ebenfalls nicht wie ich das prüfen soll, wenn das überhaupt möglich ist. Hm wie ich fehlerhafte Interrupts feststelle weiß ich jetzt auch nicht. Ich dachte da auch noch an ein BIOS Update. Sinnvoll oder nicht? Ein Kollege meinte noch ich solle für die Installation mal alle Festplatten abstecken und nur die eine SSD dran lassen. Zudem meinte er ich solle den AHCI Treiber installieren wenn nicht schon vorhanden. Das müsste ich mal zuhause prüfen. Aber auf der Gigabyte Website gibt es einen Treiber Was wenn ich kein Floppy Laufwerk habe. Ob er den Treiber auch von der DVD lesen kann?! Dann würd ich ne neue WIN7 Installations-DVD brennen mit dem Treiber drauf. LG Gateway
-
Hallo liebe Leute, ich habe mir eine neue SSD Festplatte (Crosair Force GS 240 GB) gekauft. Ich habe diese verbaut und im Bios wird diese auch ordnungsgemäß angezeigt. Meine alte primär SSD auf der bereits ein Windows 7 64 Bit läuft hab ich vorsichtshalber mal abgesteckt (man weiß ja nie was bei der Installation alles schiefgeht). An der Stelle wollte ich noch anmerken das in meiner Kiste kein DVD Laufwerk verbaut ist und ich das ganze über ein DVD Laufwerk das per USB angeschlossen ist, abwickle. Ich hab also mit meiner Windows 7 Installations-DVD gebootet und die Installation lief reibungslos durch. Gestartet hat er auch (auch von der Festplatte). Jetzt hab ich die Bootreihenfolge wieder geändert (Statt USB-DVD an erster Stelle habe ich Harddisc gewählt). Jetzt sagt mir das System das es kein Operating System gefunden hat. Pack ich das USB-DVD Laufwerk wieder an erster Stelle und leg die Windows Installation ein, startet er plötzlich wieder von der Festplatte (ganz sicher nicht von der DVD). Sehr seltsames verhalten. Ich hatte dann nochmal nen anderen SATA Anschluss am Mainboard versucht und das System nochmal neuinstalliert. Das Ergebnis bleibt das gleiche. Beim dritten Versuch hab ich meine alte SSD wieder angeschlossen und diese als zweites in der Bootreihenfolge (direkt nach der neuen SSD) gestellt. Installation von Windows lief durch und beim ersten Neustart nach der Installation konnte ich noch zwischen den Windows Installation auswählen (beim Booten). Nach kompletter Fertigstellung hab ich das System nochmal neugebootet. Es kam kein Auswahldialog nach dem Bios Screen und er hat wieder von meiner alten SSD gebootet (obwohl diese an zweiter Stelle in der Bootreihenfolge steht). Jetzt sitz ich hier seit 4 stunden für ne simple Windows Installation und verlier fast den Verstand. Ein solches Verhalten hatte ich noch nie. Dann hab ich das Reperaturprogram von der DVD ausprobieren wollen. Dort gibt es die Option mit der Beschreibung: "Wenn Ihr System nichtmehr startet". Das hab ich dann ausgewählt und ich musste lachen. Es kam die Meldung schließen Sie alle USB Devices von Ihrem Rechner ab, starten Sie diesen dann neu und führen Sie diese Aktion erneut aus (wie bereits erwähnt verfüge ich nur über ein USB DVD Laufwerk :beagolisc). Hat jemand noch ne Idee? Hier noch ein paar BIOS Screens: Boot Reihenfolge mit USB Laufwerk an erster Stelle Harddisk Reihenfolge LG Gateway
-
Super, danke euch beiden. Werde mir alles mal in ruhe ansehen und ausprobieren. LG Gateway
-
Hi, ich will auf keinen Fall chm Help files. Ich will eine Website die ich auf einem IIS hosten kann. Wie gesagt strukturell soll es so aufgebaut sein wie die msdn. Gibts sowas zu kaufen? Xml Kommentare wird von der IDE sowie der Programmiersprache nicht unterstützt. LG Gateway
-
Hallo, ich bin mir nicht sicher wo ich es reinpacken soll (gehört für mich jetzt nicht zu Anwendungssoftware). Verschiebt es bitte wenn ich es in der falschen Rubrik erstellt habe. Ich suche nach einem Produkt (einer Website) die es mir erlaubt Klassen und deren member zu beschreiben. Im Prinzip genauso etwas wie die MSDN. Kann gerne etwas kosten, aber es wäre notwendig das man Zugriff auf den Quellcode für das Projekt erhält, sodass man es erweitern/ändern kann. Ist jemandem so etwas bekannt? Optimaler weise ASP.NET, PHP wäre aber auch nicht schlimm. Mein Problem ist, ich weiß nichtmal unter was für einer Begrifflichkeit ich bei Google suchen soll. Auf keinen Fall soll es ein Wiki sein. Ich check die Nutzung dieser Teile bis heute nicht. Für mich total unübersichtlich. Ein Suchfeld irgendwo oben und ansonsten links ein treeview mit den Technologien bzw. geschachtelt den Klassen und rechts die Beschreibungen. LG Gateway
-

[VC++] Probleme mit wifstream (lesend)
Gateway_man antwortete auf Gateway_man's Thema in C++: Compiler, IDEs, APIs
Ah okay. Aber auch wstring muss ja wissen wann die Zeichenkette endet. Wie ermittelt wstring denn die gültige Länge? Denn anscheinend kriegt wstring das richtig hin. Ich habe es übrigens auch statt mit wcslen mit der length Funktion des wstrings erfolglos probiert. Das sagst du so einfach . Das ist die einzige Validierungsmöglichkeit die ich habe. Meinst du das die Debugger Information falsch ist und ich es ignorieren kann? Hm. Wie macht wstring das. Der muss ja auch irgendwie die länge ermitteln?! Was ich übrigens sehr spannend finde ist: Wenn ich anstelle von wcsncpy wcscpy verwendet, zeigt er es zumindest im Designer richtig an. Ich finde das echt total irritierend. Mit deiner vektorlösung und dem wstring funktioniert es. Versuche ich dann aber irgendwie an einen nicht konstanten wchar_t Pointer zu gelangen funktioniert es nicht. Ich greife doch auf die selbe Datei zu. LG Gateway PS: @Klotzkopp: Vielen Dank für deine Hartnäckigkeit und dein Geduld . Jetzt hab ich es endlich gerafft (hat ja auch lang genug gedauert) und hab auch eine Patentlösung und muss auch nicht auf meine wchar_t Pointer verzichten. (Ja ich weiß ich sollte die Finger davon lassen, aber es gibt gewisse Abhängigkeiten) Jetzt versteh ich auch wie du das mit dem Debugger gemeint hast :upps. Danke Interessant wäre es dennoch wie wstring die länge ermittelt, sofern du dahingehend was weißt . -
[VC++] Probleme mit wifstream (lesend)
Gateway_man antwortete auf Gateway_man's Thema in C++: Compiler, IDEs, APIs
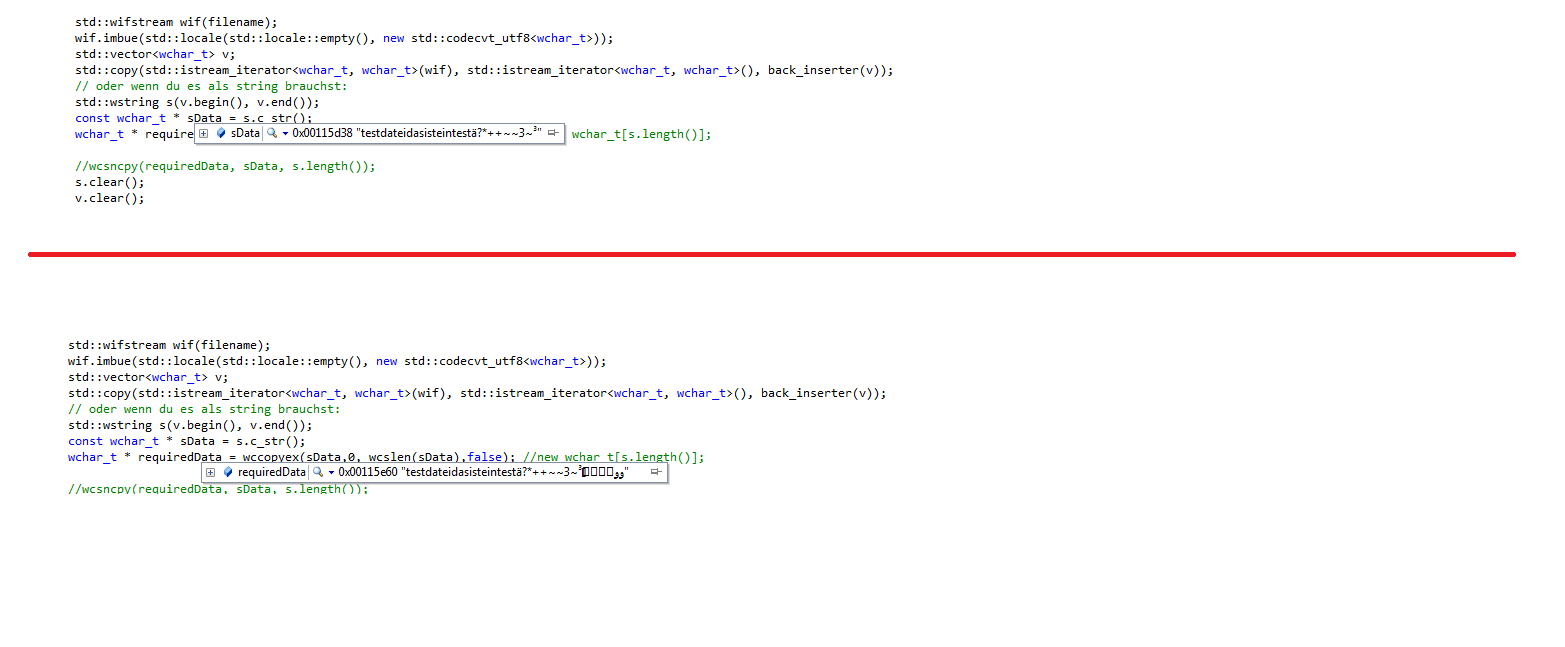
hallo, @flashpixx: Ich glaube wir beide reden aneinander vorbei. Ich weiß ehrlich gesagt beim besten willen nicht, was ich jetzt mit regex anfangen soll :confused:. Danke für deine Hilfe, aber ich versuch mich jetzt wieder an meinem ursprünglichen Problem. Aus reiner Neugier. Beinhaltet die stl überhaupt ein regex Konstrukt? @Klotzkopp: Danke für deinen Hinweis mit der Funktion wcsncpy. Tatsächlich ist es die Funktion die den Inhalt ans Ende hängt. Was ich aber jetzt noch nicht raffe ist, es scheint kein aber keine string Terminierung zu sein. Ich hab den Inhalt nach '\0' durchsuchen lassen ohne Erfolg. Ich raff das nicht. Warum sieht das konstante Array der std::wstring korrekt aus und am unteren Array hängt wieder der mist dran. Also für mich sieht der Schwachsinn am Ende nicht nach einer Null Terminierung aus. Ich hab mir eine eigene "copy" Funktion geschrieben, in der Hoffnung das sich das dann erledigt hat. wchar_t * wccopyex(const wchar_t * input, const size_t index, const size_t count, bool wcsterminate) { wchar_t * result = 0; if (input != 0) { int ia = std::wcslen(input); if (index + count <= ia) { result = new wchar_t[(wcsterminate ? (count + 1) : count)]; for (int i = 0; i < count; i++) { result[i] = input[index + i]; } if (wcsterminate) result[count] = '\0'; } } return result; } Das hat wie man im Screenshot sieht nicht geklappt. Stellt sich raus das er die letzten paar Indexe schon bei der Initialisierung des Arrays setzt. Mir ist gerade aufgefallen, das das result Array auch 40 Elemente hat, was spannend ist, da das eingabe Array lediglich 32 Elemente hat. Ich werde noch irre. Ich flipp echt bald noch aus. Ich will doch lediglich ein nicht konstantes wchar_t Array. Ist das denn zu viel verlangt. Einen ganzen Tag beschäftigt mich der Unfug jetzt schon.... Etwas so triviales das in jeder anderen Sprache in einem drei Zeiler gemacht werden kann und kein absonderliches verhalten verursacht. Quasi die ganze Logik der dahinter liegenden Library arbeitet mit wchar_t Arrays. Aber so brauch ich nichtmal versuchen den Mist zu übergeben....... Ich geh jetzt mal mein Rechner gegen die Wand werfen... LG Gateway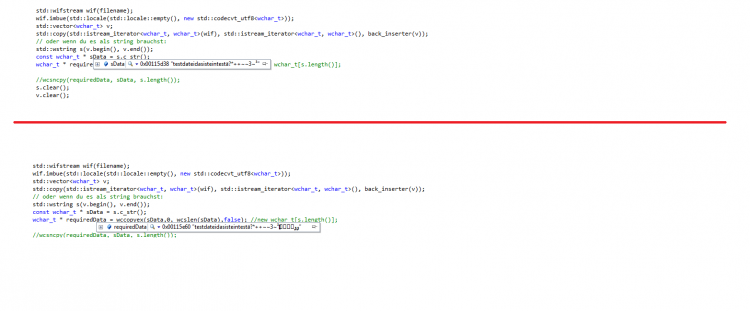
-
[VC++] Probleme mit wifstream (lesend)
Gateway_man antwortete auf Gateway_man's Thema in C++: Compiler, IDEs, APIs
Verstehe gerade nicht was du mir damit sagen willst. Ich weiß auch das es geht. Aber es ist umständlich. Hier ein Beispiel: Ich iteriere ein char Array durch um nach diversen sequenzen zu suchen. wenn ich jetzt prüfen möchte ob der aktuelle character ein match ist, geht das nicht so einfach: if (currentCharacter == 0xe0b8bf) { // hier wird er nie reingehn. Die Bedinung kann nie erfüllt werden, weil der Wertebereich nie groß genug sein wird. // ich hab im Netz schon obskure Lösungswege gesehn. Bis hin zu einer Funktion die immer zwei character eingelesen hat und diese dann miteinander mulitpliziert hat. Aber das war mir zu strange und zu Aufwändig. } Das sah für mich einfach nach zu viel rum gefriggel aus. Daher wchar_t. Da hab ich auch den Vorteil das ich easy auf utf-32 wechseln kann. Und auf fremde Libraries greif ich nur sehr ungern zurück. Also ist Boost jetzt nicht wirklich für mich eine alternative. -
[VC++] Probleme mit wifstream (lesend)
Gateway_man antwortete auf Gateway_man's Thema in C++: Compiler, IDEs, APIs
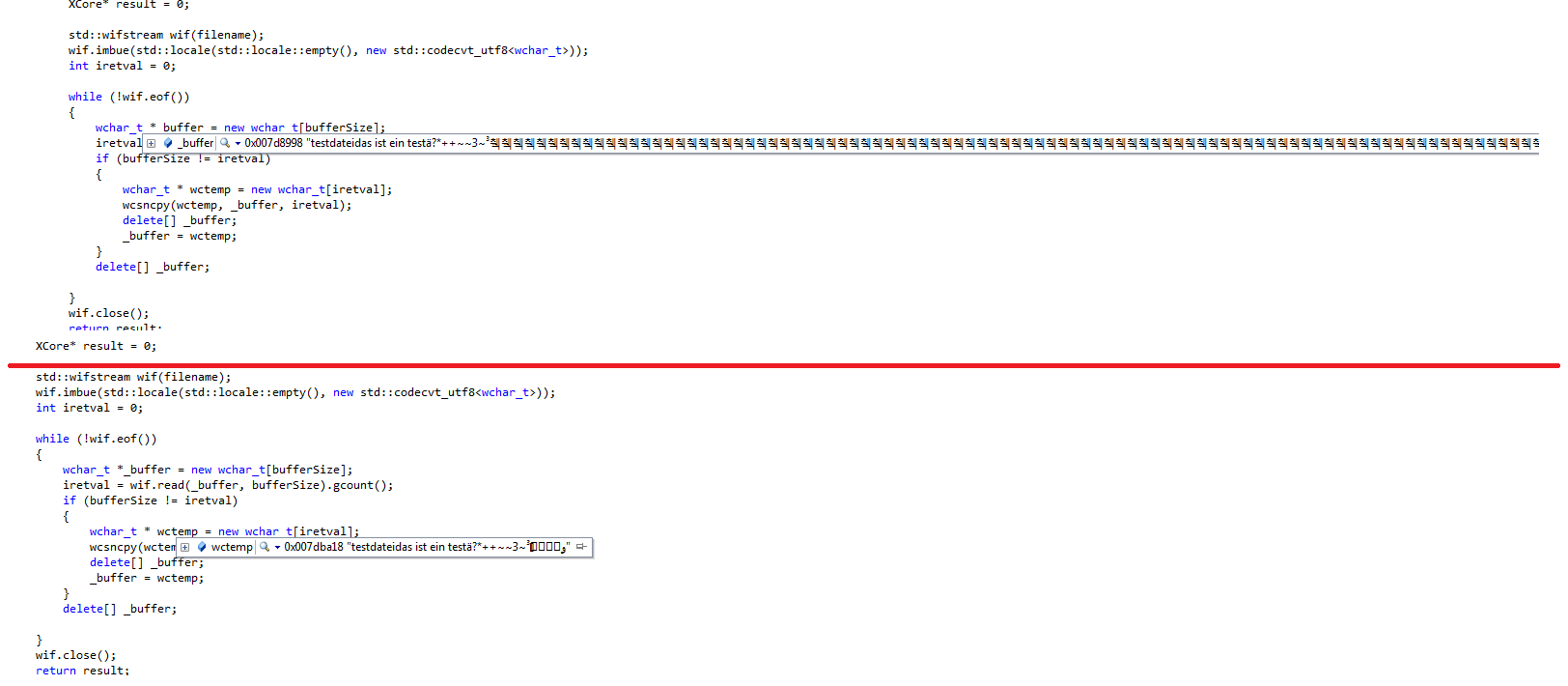
Ja. Ich kenne aber auch keine Funktion die nicht von einer Nullterminierung ausgeht. Ich meine woher soll die Funktion dann wissen wann das Ende der Zeichenkette erreicht ist. Ich versteh nicht warum am Ende kein \0 ist. Ich meine nach meinem Verständnis muss doch eigentlich jede Zeichenkette eine Terminierung haben sonst kann man nicht sinnvoll damit arbeiten. Woher soll xyz Funktion wissen, wann die Zeichenkette zu Ende ist?! Ich hab versucht das ganze von Anfang an abzufangen. Also das ursprungsarray schon mit der richtige größe zu erstellen, wenn die Dateigröße kleiner ist als die Buffersize. std::wifstream wif(filename); if (wif.is_open()) { wif.imbue(std::locale(std::locale::empty(), new std::codecvt_utf8<wchar_t>)); int iretval = 0, fileSize = -1; wif.seekg(0, std::ios::end); fileSize = wif.tellg(); wif.seekg(0); if (fileSize > 0 && fileSize < bufferSize) { wchar_t *_buffer = new wchar_t[fileSize]; wif.read(_buffer, fileSize); //Do Something delete[] _buffer; } else { while (!wif.eof()) { wchar_t *_buffer = new wchar_t[bufferSize]; iretval = wif.read(_buffer, bufferSize).gcount(); if (bufferSize != iretval) { wchar_t * wctemp = new wchar_t[iretval]; wcsncpy(wctemp, _buffer, iretval); delete[] _buffer; _buffer = wctemp; } delete[] _buffer; } } wif.close(); } Aber das hat mir nichts gebracht.... LG Gateway -
[VC++] Probleme mit wifstream (lesend)
Gateway_man antwortete auf Gateway_man's Thema in C++: Compiler, IDEs, APIs
Das am ende sind keine 0 Werte. Die letzten werte im Array sind 65021. Was mich stört ist das das Array größer ist als der eigentliche Inhalt. Ich hatte die Hoffnung, das ich das Array so resizen kann, das nur noch der relevante Inhalt drin ist. Muss ich das im nachhinein nochmal durchiterieren und händisch rausschmeißen?! So kann ich es nicht lassen, sonst steigt meine Routine aus, welche die Datenstruktur validiert, weil sie 65021 als invalid erachtet. LG Gateway -
[VC++] Probleme mit wifstream (lesend)
Gateway_man antwortete auf Gateway_man's Thema in C++: Compiler, IDEs, APIs
Hi, danke für die schnelle Antwort. Vielleicht ein kurz ein paar Informationen warum ich das so gemacht habe. Warum lese ich nicht die ganze Datei ein? Die Zieldatei kann mehrere GB groß sein und wenn es fertig ist, wird die Funktion & deren "Analysefunktionen" in einem eigenen Thread ausgelagert. Es soll dann die Möglichkeit existieren den Vorgang abzubrechen wenn es zu lange dauert. Wenn ich aber ein komplettes Read mache, wüsste ich nicht wie ich das sauber abbrechen könnte. Zusätzlich kann es sein das das lesen der Datei selbstständig abgebrochen wird, da er abbrechen soll, wenn er bei der Analyse einen Strukturfehler findet. Deswegen iteriere ich durch. Am Ende wird in der Schleife dann noch eine Ausstiegbedingung reinkommen. Ein vector habe ich deswegen nicht genommen, da der eingelesene Inhalt in einer anderen Funktion aufbereitet wird (viele wchar_t character werden rausgelöscht). Soweit ich das verstanden habe, ist ein vector nicht dafür geeignet bzw. ist sehr langsam wenn es viele Inhalte gibt und diese auch öfters entfernt oder verändert werden. Wenn überhaupt dann würde ich evtl als alternative ne std::list hernehmen. Allerdings kann ich da nicht auf den Index zugreifen und müsste tatsächlich immer durchiterieren. Hm ich war der Meinung das char Unicode nicht handlen kann. Meines wissen ist der Wertebereich eines chars -127 bis 127. Auch ein unsinged char (255) kann ja nichtmal ansatzweise die UTF8 geschweige denn die UTF16 Tabelle abbilden. Da müsste ich dann ja immer mit zwei charactern arbeiten um ein Zeichen abzubilden. Das ist mir zuviel Aufwand. Da nehm ich lieber gleich den Typ der dafür vorgesehn ist. Ich habe mal ein Screenshot zusammengebastelt um das Problem genauer darzustellen. Ich kann mir das ehrlich gesagt nicht erklären. LG Gateway PS: @Klotzkopp: Zudem verlangen die ganzen tollen wc Funktionen immer Arrays. Da dachte ich, bleib ich lieber gleich bei Arrays, anstatt mir jedesmal vom Container ein Array zu holen.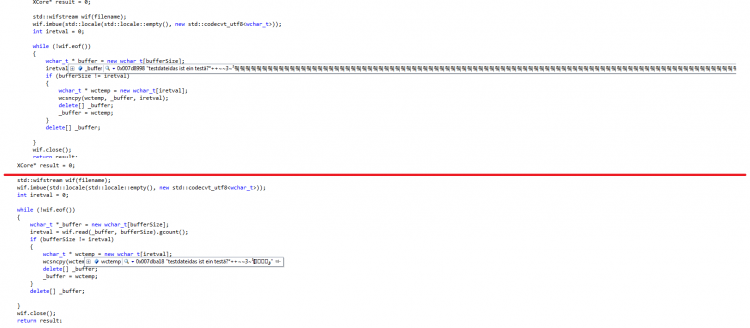
-
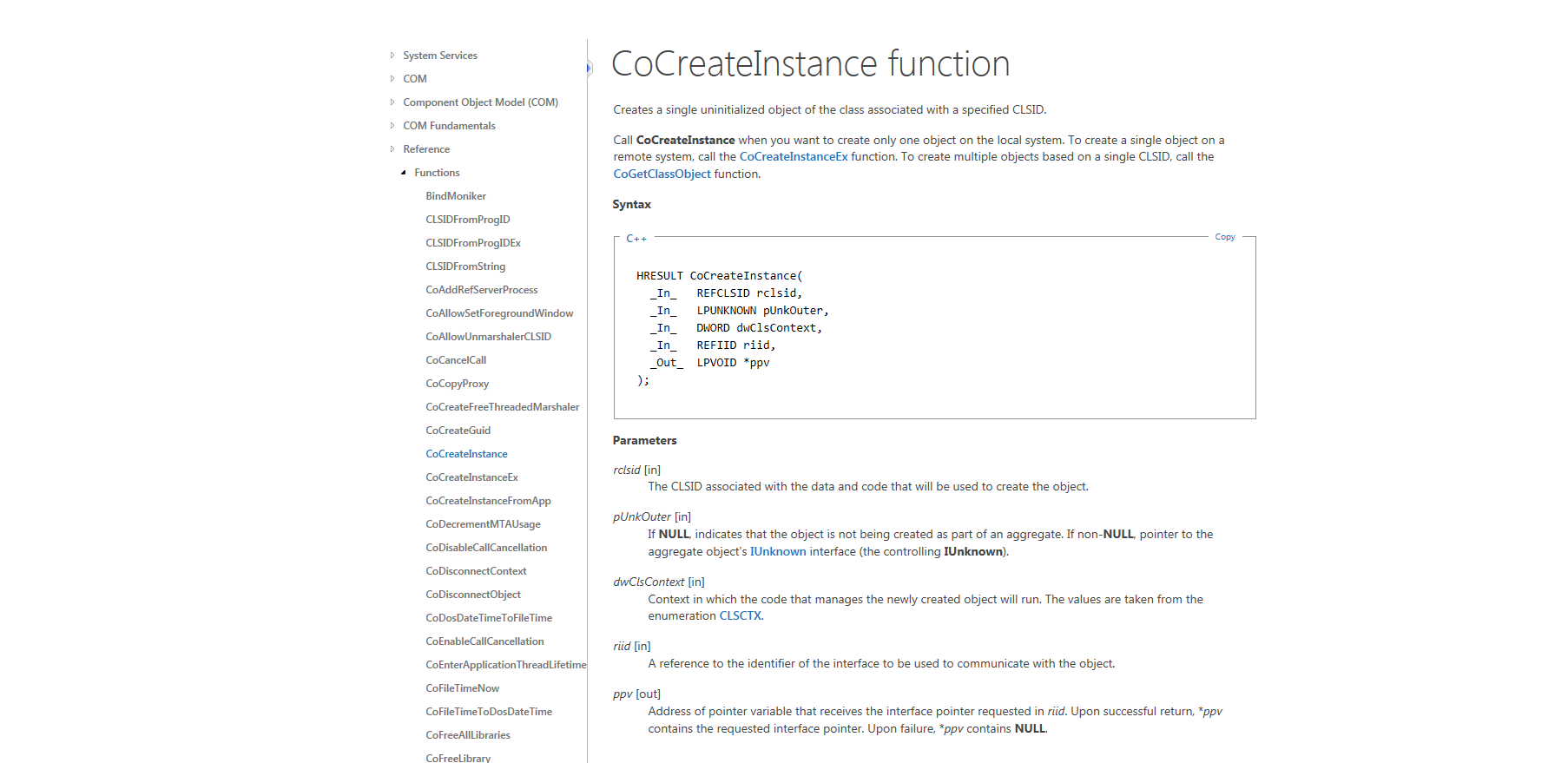
Hallo, zu erst einmal eine Frage vorweg. Ist der wifstream obsolet oder hoch kritisch? Ich finde total wenig wenn ich im Netz nach meiner Problematik suche. Meistens finde ich dann Beispiele mit ifstream... Ich will mit dem wifstream immer gebuffered den Inhalt einer Datei auslesen. Also nicht alles auf einmal sondern man soll der Funktion eine Buffersize mitgeben können. Das ganze sieht wie folgt aus: XCore* XCore::LoadFile(const std::wstring& filename,const int bufferSize = 4096) { XCore* result = 0; std::wifstream wif(filename); wif.imbue(std::locale(std::locale::empty(), new std::codecvt_utf8<wchar_t>)); int iretval = 0; while (!wif.eof()) { wchar_t *_buffer = new wchar_t[bufferSize]; iretval = wif.read(_buffer, bufferSize).gcount(); if (bufferSize != iretval) { wchar_t * wctemp = new wchar_t[iretval]; wcsncpy(wctemp, _buffer, iretval); delete[] _buffer; _buffer = wctemp; } delete[] _buffer; } wif.close(); return result; } Nicht wundern. Ich wollte die Funktion erstmal per Debugger testen, bevor ich mit dem Inhalt weiter verfahre. Und schon hatte ich einen Fehler gefunden. Mein Problem ist das gcount() immer falsche werte zurückliefert. Momentan läuft er immer in die Verzweigung rein die das Array resizen soll. Leider wird das Temporäre Array immer zu groß definiert. Sieht jemand jetzt schon einen gravierenden Fehler? Ansonsten würd ich mit weiteren Infos aufwarten. LG Gatway
-
[VC++] Exceptionhandling mit unique_ptr
Gateway_man antwortete auf Gateway_man's Thema in C++: Compiler, IDEs, APIs
Danke für deine Hilfe. Ich werde mir das mal angewöhnen. -
[VC++] Exceptionhandling mit unique_ptr
Gateway_man antwortete auf Gateway_man's Thema in C++: Compiler, IDEs, APIs
Danke für deine Hilfe. Habs hinbekommen . Ich habe die rohe Zeigervariable in ExceptionBase rausgeschmissen (Wie du es mir immer sagst. Finger weg von rohen Zeigern ). Jetzt musste ich leider einen Standartkonstruktor für StackFrame erstellen (Parameterlos) und das wollte ich eigentlich nicht . Um das ganze zu lüften: struct StackFrame { private: int _line; std::string _assembly, _functionname, _filename; public: //Standartkonstruktor hinzugefügt StackFrame(); StackFrame(int lineNumber, std::string assembly, std::string functionName, std::string filename); int Line(); std::string Assembly(); std::string FunctionName(); std::string Filename(); }; StackFrame::StackFrame() { } StackFrame::StackFrame(int lineNumber, std::string assembly, std::string functionName, std::string filename) { _line = lineNumber; _assembly = assembly; _functionname = functionName; _filename = filename; unsigned pos = _filename.find_last_of("\\"); if (pos >= 0) _filename = _filename.substr(pos +1); } int StackFrame::Line() { return _line; } std::string StackFrame::Assembly() { return _assembly; } std::string StackFrame::FunctionName() { return _functionname; } std::string StackFrame::Filename() { return _filename; } Hier die ExceptionBase Klasse (Änderungen auskommentiert!): class ExceptionBase { private: long _errorcode, _oserrorcode; std::string _message; //StackFrame* _stackframe; StackFrame _stackframe; public: ExceptionBase(int errorcode, int oserrorcode, std::string _message, /*StackFrame* frame*/ StackFrame& frame); long ErrorCode(); long OsErrorCode(); ~ExceptionBase(); std::string Message(); //StackFrame* GetStackFrame(); StackFrame GetStackFrame(); }; ExceptionBase::ExceptionBase(int errorcode, int oserrorcode, std::string message, /*StackFrame* frame*/ StackFrame& frame) { _errorcode = errorcode; _oserrorcode = oserrorcode; _message = message; _stackframe = frame; } ExceptionBase::~ExceptionBase() { //if (_stackframe != 0) // delete _stackframe; } long ExceptionBase::ErrorCode() { return _errorcode; } long ExceptionBase::OsErrorCode() { return _oserrorcode; } std::string ExceptionBase::Message() { return _message; } //StackFrame* ExceptionBase::GetStackFrame() //{ // return _stackframe; //} StackFrame ExceptionBase::GetStackFrame() { return _stackframe; } LG & Danke Gateway -
[VC++] Exceptionhandling mit unique_ptr
Gateway_man antwortete auf Gateway_man's Thema in C++: Compiler, IDEs, APIs
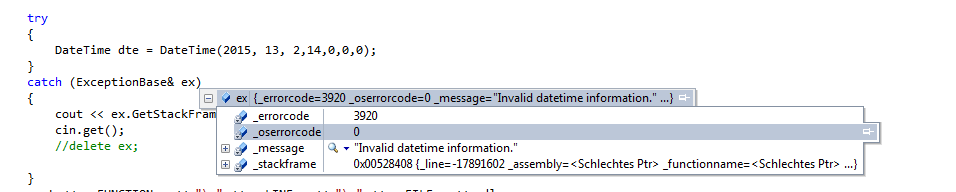
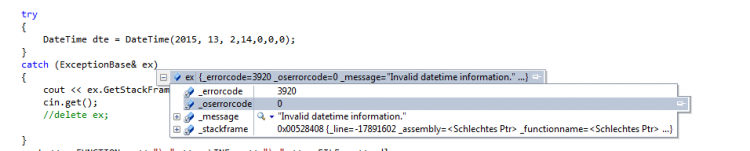
Hi, danke für deine fixe Antwort. Aber das habe ich bereits ausprobiert, leider mit mäßigem Erfolg. Alle werte des ExceptionBase Objekts die keine Pointer sind, sind zugreifbar, alle anderen sind wieder <schlechtes ptr> und ich kassier nach dem Catch Block eine Fehlermeldung (ungültiger Speicherzugriff...). So wird die Exception geworfen: Und so sieht das Handling aus (beachte was in dem Contextmenü bei _stackframe steht): LG Gateway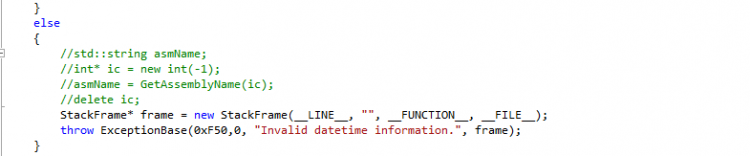
-
Hallo, du must einen Funktionszeiger "registrieren", damit du die Keyboard Messages erhältst. Hier findest du ein ganz gutes Beispiel. Vergiss aber nicht CallNextHookEx aufzurufen, ansonsten erhält nur noch deine Anwendung Keyboard Messages. LG Gateway
-
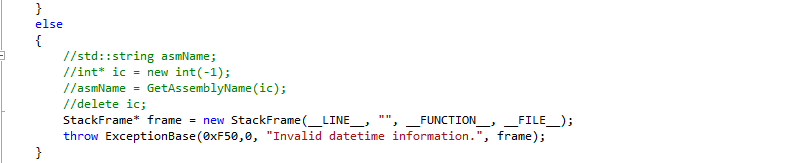
Hallo, eventuell mach ich mir momentan zu viele Gedanken darüber, dennoch kann ich das jetzt so nicht stehen lassen. Ich schreibe mir momentan eine Basisklasse welche ich für das Exceptionhandling verwenden will. Diese Klasse beinhaltet ein paar Pointer variablen. Wenn ich jetzt den Fehler jetzt wie folgt werfe: throw ExceptionBase(.....); Dann habe ich folgendes Phänomen im Catch Block: Alle Felder sind richtig bis auf die Pointer Variablen. Deren Wert ist überall <schlechtes ptr> (steht wirklich so drin nicht mein grammatikalischer Fehler). Ich lehn mich jetzt mal weit aus dem Fenster und vermute mal das er eine Kopie des ExceptionBase Objekts macht und dabei Probleme mit den Pointern hat. (Wie C++ sich beim Exceptionhandling wirklich verhält, entzieht sich jedoch meinen Kenntnissen) Das Problem kann ich beheben indem ich das ExceptionBase Objekt beim Throw als Pointer erzeugen lasse: throw new ExceptionBase(.....); Ich hatte jetzt nur etwas schiss, das wenn ich das so überall mache und ich irgendwo mal vergesse im Catch Block den Pointer zu handlen, das ich dann Speicherleaks verursache. Also habe ich versucht einen Smart Pointer beim throw zu erzeugen: throw std::unique_ptr<ExceptionBase>(new ExceptionBase(0xF50,0, "Invalid datetime information.", frame)); Da meckert er noch nicht und alles scheint super. Allerdings meckert er beim Catch Block: catch (std::unique_ptr<ExceptionBase> ex) Dort bringt er folgenden fehler: Das liegt offensichtlich daran das der Destruktor von unique_ptr nicht öffentlich zugänglich ist. Wie würdet ihr das Lösen? Ich spiel jetzt gerade mit dem Gedanken mir ein eigenes "Smart Pointer" Template zu schreiben, das über einen öffentlichen Destruktor verfügt. LG Gateway
-
Hallo, ich stelle mir momentan die Frage wie viele Verbindungen ein heutzutage guter Server verwalten kann. In diesem Kontext wollte ich den Site-Admin mal fragen ab wann es bei "fachinformatiker.de" eng wird? Wie viele simultane Verbindungen verkraftet der Webserver. Hat man das schon mal ausgelotet? Warum ich das Frage. Ich arbeite momentan an einem NAT Server und versuche momentan auszuloten, was ein einziger Server verkraftet bzw. wie viele Server ich theoretisch benötige. Lg Gateway
-
[C#] Generiere mehrere Öffentliche Schlüssel aus einem privaten Schlüssel
Gateway_man antwortete auf Gateway_man's Thema in .NET
Danke dir für die Information. TLS scheint ja eine Kombi aus RSA und AES zu sein. Das ganze klingt eigentlich genau nachdem was ich gesucht habe, passt aber leider nicht in mein aktuelles Klassenkonzept. Dafür müsste ich den SslStream nutzen und das krieg ich so nicht hin ohne die ganze Klassenhierarchie über den Haufen zu werfen. Eventuell hab ich etwas mit den Infos gegeizt. Daher kommt jetzt das ganze Packet. Ich schreibe aktuell eine Socket Klasse, welche um immens viele Funktionalitäten erweitert werden sollte. Der Grund? Da ich relativ viel mit Netzwerkprogrammierung mache, hab ich so ein paar Dinge kennengelernt, die mich jedes Mal fast in den Wahnsinn treiben. Beispielsweise den genauen Status der Verbindung (bei der Socket Klasse des .NET Frameworks ist der Status einer Verbindung faktisch nicht ohne eine Interaktion mit der gegenstelle zu ermitteln). Ich will zu jeder Zeit ohne jegliche Zusatzoperationen den aktuell gültigen Status der Verbindung abfragen können. Zudem möchte ich ebenfalls die Möglichkeit haben, gewisse Events abfangen zu können (Beispielsweise bei Verbindungsabbrüchen). Jetzt gibt es folgende Zustände: [Flags] public enum SocketConnectionState { Unknown = 0x0, NotInitialized = 0x1, AcceptingSync = 0x2, AcceptingAsync = 0x4, Listening = 0x8, Connecting = 0x10, ConnectingAsync = 0x20, Etablished = 0x40, Lost = 0x80, Disconnecting = 0x100, DisconnectingAsync = 0x200, Disconnected = 0x400, Sending = 0x800, SendingAsync = 0x1000, Receiving = 0x2000, ReceivingAsync = 0x4000, SendClosed = 0x8000, ReceiveClosed = 0x10000, Closed = 0x20000, SendingKeepAlivePackage = 0x40000, ReceivingKeepAlivePackage = 0x80000 }; Man hat die Möglichkeit dem Socket eine KeepAliveDefinition zu übergeben, in der man das Interval und auch das Datenpacket festlegen kann. Jetzt kam zusätzlich noch der Wunsch dazu, das man dem Socket direkt einen "Cryptography Layer" übergeben kann. Somit soll der Socket sich selbst um die korrekte Verschlüsselung/Entschlüsselung kümmern. Dafür verlangt die Socket Klasse jetzt eine Klasse die das Interface ICryptoLayer implementiert: public interface ICryptoLayer { bool IsHybrid { get; } bool CanChangeEncryptionMode { get; } SocketEncryptionDirection EncriptionDirection { get; } bool CanEncrypt { get; } bool CanDecrypt { get; } bool IsBlockchiffre { get; set; } int BlockSize { get; set; } HybridEncriptionState CryptoState { get; } byte[] Encrypt(byte[] input); bool TryEncrypt(byte[] input, out byte[] output); byte[] Decrypt(byte[] input); bool TryDecrypt(byte[] input, out byte[] output); bool ChangeCryptoMode(); bool Inheritable { get; set; } } Da prinzipiell jedes Verschlüsselungsverfahren unterstützt werden soll, gibt es aktuell drei Klassen die von dem Interface erben: --> SymmetricCryptoLayerCfg (Verlangt im Konstruktor einen Typen der von der Klasse SymmetricAlgorithm erbt) --> AsymmetricCryptoLayerCfg (Verlangt im Konstruktor einen Typen der von der Klasse AsymmetricAlgorithm erbt) --> HybridCryptoLayerCfg (Verlangt im Konstruktor zum einen eine SymmetricCryptoLayerCfg Instanz und eine AsymmetricCryptoLayerCfg Instanz). Beispielsweise kann ich jetzt bei der Verwendung von Hybriden Verfahren bequem über die Property CryptoLayer der Socket Klasse zwischen den einzelnen Techniken wechseln. Und auch um die Verschlüsselung muss ich mich nichtmehr kümmern. Wenn ich die Daten verschlüsselt übertragen möchte, muss ich lediglich dem Socket die entsprechende Verschlüsselungsschicht übergeben. Dann übergebe ich die Daten wie man das bei einem normalen Socketobjekt auch macht. Intern kümmert sich die Socketklasse selbst um die Verschlüsselung/Entschlüsselung. Die größte Hürde war definitiv die Kryptographie Schicht. Harmoniert aber jetzt endlich wunderbar . Danke @ all. Lg Gateway