tkreutz2
User
-
Registriert
-
Letzter Besuch
-
Der ursprüngliche Beitrag wurde von mir bereits öffentlich eingeordnet. Mehr habe ich dazu nicht hinzuzufügen.
-
Vergesst den Beitrag bitte, die Idee dahinter war gut, aber die Ki-gestützte Unterstützung schlecht. Da ich den Ausgangsbeitrag nicht mehr löschen kann, kann ich das nur in dieser Form kommentieren. Tut mir leid, war die Idee, ein Thema in einem Bild zu visualisieren, was leider in die Hose ging. Meine ursprüngliche Idee war eigentlich eine Analogie zu einem Reel, was in Social Media existiert, bei dem ein Saal von Mönchen die Bibel mit der Hand transkribieren und dann der Chef kommt und sagt, wir haben leider eine kleine Änderung, der Name (von jemandem der in der ganzen Bibel durchgend genannt wird) ist doch nicht X sondern Y. Die Aufgabe der Ki war eigentlich dieses Thema in einem Bild zu visualisieren, dass kleine Änderungsanforderungen große Folgen nach sich ziehen können. Da wir mit Ki-Themen in neue Bereich vordringen und "glauben" die Produktivität steigern zu können, aber dabei vergessen, dass dadurch auch Nebeneffekte entstehen können, wollte ich eine Analogie von zwei Themen in einem Bild haben. Das ging leider in die Hose, das Bild ist jetzt völlig überladen, enthält Fehler in der mathematischen Darstellung und das Kernthema kann auch nicht mehr visualisiert werden. Also ein Fail, wenn ich so wollte. Mir ist das auch erst später klar geworden, als ich das Bild noch einmal genauer betrachtet hatte. Das große Projekt, an dem ich immer noch arbeite, ist das Thema Ki gestützte Entscheidungsräume. Auf diesem Gebiet konnte ich den letzten 3 Monaten ein Menge Artefakte erzeugen, die ich noch am sortieren bin. Wen es interessiert, den kann ich gerne per PN einen aktuellen Stand dazu senden. In diesem Sinne ! Schönes Wochenende Allen !
-
 Dakta hat auf einen Beitrag in einem Thema reagiert:
Entscheidungsräume, Wissenssysteme und der Erhalt menschlicher Souveränität
Dakta hat auf einen Beitrag in einem Thema reagiert:
Entscheidungsräume, Wissenssysteme und der Erhalt menschlicher Souveränität
-
 hackbert301009 hat auf einen Beitrag in einem Thema reagiert:
Mietpreise Europa - DE günstig im Vergleich
hackbert301009 hat auf einen Beitrag in einem Thema reagiert:
Mietpreise Europa - DE günstig im Vergleich
-
hackbert301009 hat auf einen Beitrag in einem Thema reagiert:
Ein alternativer Ansatz zur Bewertung von Fachinformatiker-Projektanträgen
-
hackbert301009 hat auf einen Beitrag in einem Thema reagiert:
Entscheidungsräume, Wissenssysteme und der Erhalt menschlicher Souveränität
-
Hallo zusammen, ich beschäftige mich seit einiger Zeit mit der Analyse von Fachinformatiker-Projektanträgen und den dazugehörigen Diskussionen, insbesondere bei Grenzfällen. (Mit Hilfe eines Ki-Modells). Dabei ist mir aufgefallen, dass viele Bewertungen stark über Begriffe wie: - Komplexität - Umfang - Entscheidungsspielraum - Technikanteil geführt werden. Ich habe deshalb versucht, ein einfaches Prüfmodell zu entwickeln, das die bisherigen Beobachtungen strukturierter beschreibt. Die zentrale Hypothese lautet: > Nicht die Entscheidungstiefe ist der erste Prüfpunkt, sondern der Berufsbild-Fit der eigentlichen Kernaktivität. Das Modell arbeitet aktuell mit folgender Prüfkette: Netto-Kernaktivität ↓ Berufsbild-Fit ↓ Entscheidungstiefe ↓ Skalierung ↓ Votum ## Kerngedanke Zunächst wird versucht, die tatsächliche Kernarbeit eines Projekts zu bestimmen. Dabei werden Produktnamen und Buzzwords gedanklich entfernt. Beispiele: - SharePoint - SQL Server - Cisco - Microsoft 365 - Power Platform sagen zunächst wenig über das Berufsbild aus. Entscheidend ist die Frage: > Welche fachliche Arbeit wird eigentlich durchgeführt? Beispiele: ### Eher Fachinformatiker Systemintegration - Infrastrukturintegration - Serverbetrieb - Netzwerkdesign - Systemhärtung - Rechte- und Berechtigungskonzepte - Betriebs- und Sicherheitskonzepte ### Eher Fachinformatiker Anwendungsentwicklung - Workflowlogik - Datenmodellierung - Formularlogik - Geschäftsprozessabbildung - Status- und Freigabelogiken - Anwendungsverhalten ## Daraus ergibt sich eine These Ein Projekt kann - technisch anspruchsvoll, - komplex, - und entscheidungsreich sein, aber trotzdem für das gewählte Berufsbild ungeeignet sein. Umgekehrt kann ein Projekt mit gutem Berufsbild-Fit zunächst zu dünn wirken, aber durch fachlich passende Vertiefung tragfähig werden. ## Beispiel Ein Projekt auf Basis von Microsoft 365 oder SharePoint ist nicht automatisch ein FiSi-Projekt. Die entscheidende Frage wäre: > Besteht die Kernarbeit in Bereitstellung, Integration, Betrieb und Absicherung der Plattform? oder > Besteht die Kernarbeit in Workflowentwicklung, Prozessmodellierung, Formular- und Geschäftslogik? Je nach Antwort könnte derselbe Produktname zu unterschiedlichen Berufsbild-Einordnungen führen. ## Offene Fragen Mich würde interessieren: 1. Haltet ihr die Trennung von Berufsbild-Fit und Entscheidungstiefe für sinnvoll? 2. Habt ihr Beispiele, bei denen ein Projekt wegen des falschen Kompetenzraums abgelehnt wurde, obwohl genügend Entscheidungen vorhanden waren? 3. Wo seht ihr Schwächen dieses Ansatzes? 4. Welche Gegenbeispiele würden das Modell widerlegen? Mein Ziel ist ausdrücklich nicht, eine IHK-Regel zu formulieren, sondern ein Analysemodell zur Diskussion zu stellen. Ich freue mich über Kritik, Gegenbeispiele und Falsifikationen. Muster_PA.pdf
hackbert301009 hat auf einen Beitrag in einem Thema reagiert:
Pilotprojekt: High-Performance macOS-App (C++20/Metal) komplett von KI bauen lassen – Ein Erfahrungsbericht
hackbert301009 hat auf einen Beitrag in einem Thema reagiert:
Pilotprojekt: High-Performance macOS-App (C++20/Metal) komplett von KI bauen lassen – Ein Erfahrungsbericht
hackbert301009 hat auf einen Beitrag in einem Thema reagiert:
Pilotprojekt: High-Performance macOS-App (C++20/Metal) komplett von KI bauen lassen – Ein Erfahrungsbericht
hackbert301009 hat auf einen Beitrag in einem Thema reagiert:
Pilotprojekt: High-Performance macOS-App (C++20/Metal) komplett von KI bauen lassen – Ein Erfahrungsbericht
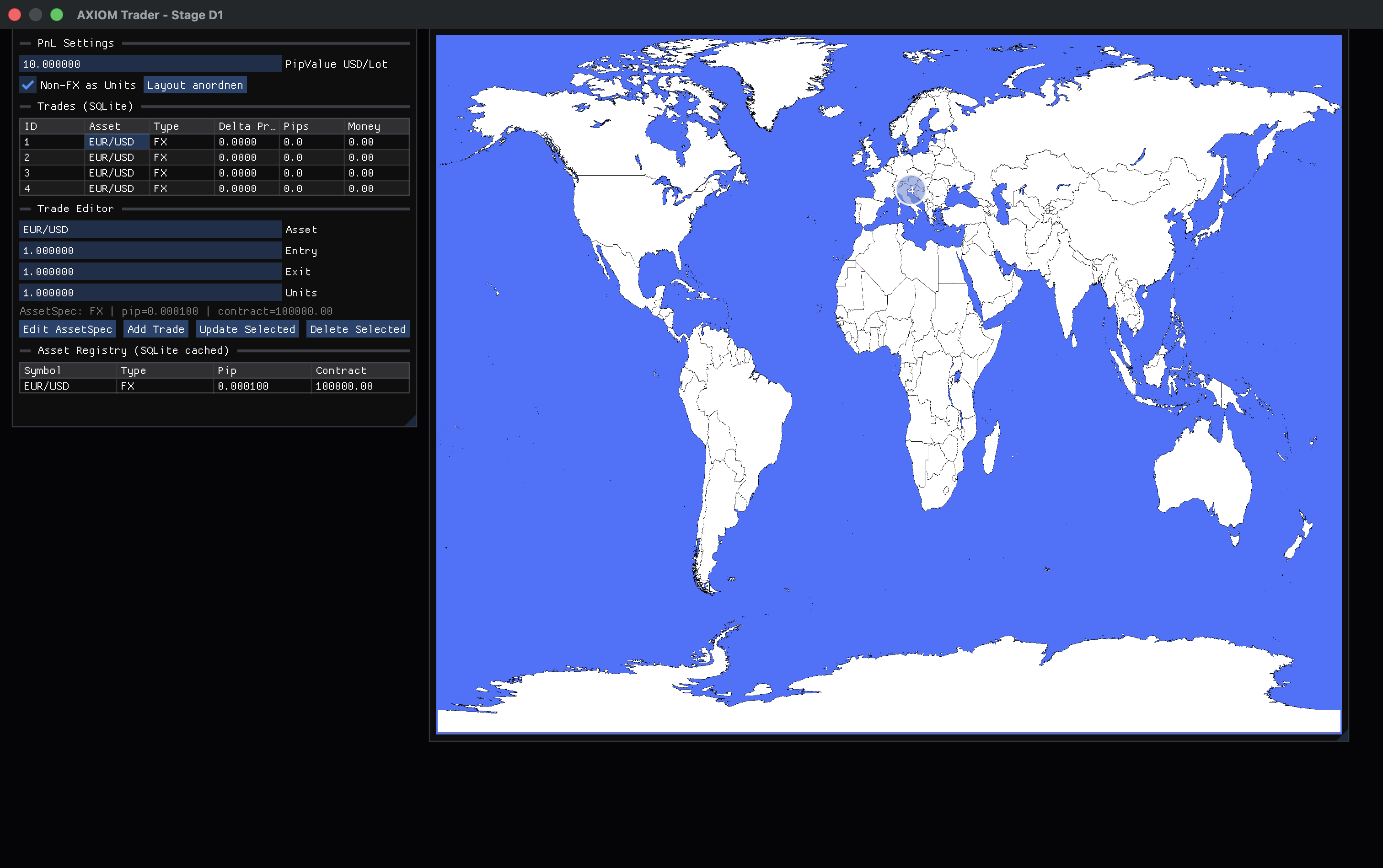
@hellerKopf Ich glaube, mein Punkt wird schnell etwas härter gelesen, als ich ihn eigentlich gemeint habe. Mir ging es weniger darum, Juniors pauschal die Fähigkeit abzusprechen, sondern eher um die aktuelle Situation im Zusammenspiel aus Ausbildung, Praxis und den sich verändernden Anforderungen. Wir haben gerade einen ziemlich starken Wandel – insbesondere durch KI. Gleichzeitig hängen Ausbildung und Qualifizierung naturgemäß immer etwas hinterher. Die spannende Frage ist für mich deshalb eher: Wie lange dauert es, bis das Wissen, das heute eigentlich schon gebraucht wird, bei den aktuell Ausgebildeten wirklich ankommt und verinnerlicht ist? Das betrifft ja nicht nur Juniors, sondern genauso bestehende Teams. Der Unterschied ist nur, dass erfahrene Leute neue Werkzeuge schneller auf vorhandene Erfahrung aufsetzen können. Daraus ergibt sich für mich dieser Effekt: Kurzfristig setzen Unternehmen stärker auf erfahrene Kräfte + KI, weil es einfach schneller Wirkung zeigt. Aber im Hintergrund entsteht damit ein gewisser zeitlicher Versatz zwischen: dem, was gebraucht wird und dem, was vermittelt wird Und genau das finde ich gerade spannend – weniger die Frage, wer etwas „kann“ oder „nicht kann“.Danke dir für den Einwand – vor allem den letzten Punkt sehe ich ziemlich ähnlich. Ich merke selbst, dass meine Aussage schnell in Richtung „KI macht alles einfacher“ gelesen wird. So war sie eigentlich nicht gemeint. Mein Eindruck ist eher: Der Einstieg wird einfacher, aber das eigentliche Problem verschiebt sich nur. Früher hast du Fehler im Code gehabt – heute hast du sie eine Ebene drüber, in der Systemdefinition. Und die sind meistens deutlich schwerer zu greifen. Was du zum Thema Ausbildung schreibst, würde ich sofort unterschreiben. Ich habe mich damit selbst mal etwas intensiver beschäftigt, weil ich genau da eine ziemliche Lücke sehe. Mein Eindruck ist: Wir bilden aktuell oft eher „Plattform-Nutzer“ aus als Leute, die Systeme wirklich verstehen oder gestalten können. Viele Lernumgebungen sind so gebaut, dass sie Komplexität verstecken – was für den Einstieg gut ist, aber langfristig auch dazu führt, dass ein echtes Systemverständnis gar nicht erst entsteht. Das wird mit KI aus meiner Sicht eher kritischer als besser. Wenn du Systeme nicht verstehst, kannst du auch nicht beurteilen, was die KI da eigentlich produziert. In dem Sinne sehe ich KI nicht als Ersatz für Fachkräfte, sondern eher als Verstärker: Gute Leute werden deutlich produktiver – aber ohne fundiertes Verständnis wird es schnell unübersichtlich. Die Diskussion um Qualifizierung hinkt da aktuell auf jeden Fall hinterher.Dieses Problem kenne ich nur zu gut und einer meiner ehemaligen Chefs hat es am besten klassifiziert. Man nennt es das "Haben-Wollen-Syndrom". Es wird kein Tag im Leben des Admins geben, der friedlich verläuft, sobald der ERSTE Mitarbeiter etwas hat, was ein anderer Mitarbeiter nicht hat. Dabei ist es Sch...Egal, ob es der größere Monitor, der Drucker, die Workstation oder sonst was ist. Aus dem Grund funktioniert IT auch nur dann in diesem Bereich erfolgreich, wenn es of der gleichen organisatorischen Ebene agiert, wie alle anderen. Wenn andere Abteilungen beispielsweise einen GF im Vorstand haben zu einem Thema, muss es die IT auch haben. Ist das nicht der Fall, wird eine solche IT sich niemals gegen andere innerhalb der Organisation durchsetzen können, weil nie Kommunikation auf Augenhöhe stattfinden wird. Und das ist ein grundsätzliches Problem der betrieblichen Organisation, seit der Erfindung der Betriebswirtschaft im akademischen Bereich. Im Grunde genommen sind sehr viele Probleme in der IT Kommunikationsprobleme und die eigentliche Herausforderungen neben dem fachlichen Wissen im Laufe einer IT-Karriere wird es immer sein, Kommunikationsprobleme zu lösen.Es ist eigentlich ganz einfach, für einen Standard Arbeitsplatz mit Office und Windows reicht auch ein Standard System aus, z.B. von HP oder auch Lenovo. https://www.notebooksbilliger.de/lenovo+thinkcentre+neo+50q+tiny+12ln008mge+889739 Wenn jemand mehr braucht, hat er halt keinen Standard Arbeitsplatzplatz und man muss dann sowieso eine an die Aufgaben / Arbeitsplatz angepasste Konfiguration z.B. Workstation machen. Wir haben ein System im Homeoffice meiner Lebensgefährtin, welches äquivalent zu ihrem Arbeitsplatz System konfiguriert worden ist (16 GB RAM), bisher gab es noch keine Probleme. (Windows 11 + Office 365 Premium Abo). Okay, wenn sich Systemanforderungen ändern z.B. durch neues Windows, neue Anwendungen, dann muss man sowieso wieder neu bewerten, in der Regel spätestens nach 4 Jahren, wenn der PC / Arbeitsplatz abgeschrieben ist. (zu Hause deutlich längere Nutzungszeit). Für Poweranwendungen hat meine Lebensgefährtin noch einen Laptop mit stärkerer Ausstattung, aber wie gesagt, der Desktop ist noch nicht an seine Grenzen gekommen. Man kann Skeptikern ja die Möglichkeit geben, einfach mal ein System auszuprobieren. Da würde ich auch nichts groß messen oder Metriken erfassen, entweder es reicht, oder es reicht nicht. Als IT-Abteilung müsst Ihr ja wissen, welche Apps sonst noch im Einsatz sind und/oder ob es irgendwo ein Nadelöhr gibt. Die meisten Sachen kristallisieren sich eh vermutlich eher im Praxisbetrieb raus, als in der Theorie. Deswegen würde ich empfehlen, rechtzeitig zu dokumentieren und zu inventarisieren. (Auch aus Sicht der Apps, damit ggf. bei künftigen Anforderungen Änderungen in der Beschaffung rechtzeitig berücksichtigt werden können).Guter Punkt – und ich glaube, genau da liegt der eigentliche Kern der ganzen Diskussion. Du beschreibst im Grunde das klassische Problem der Softwareentwicklung: Spezifikation und Implementierung driften auseinander – selbst wenn man sich noch so viel Mühe gibt. Der Unterschied, den ich im Projekt gerade konkret sehe (AXIOM Trader): Bei menschlichen Entwicklern wird ein Teil dieser Lücke meist durch Erfahrung und Intuition kompensiert. Bei der KI fällt diese Kompensation komplett weg – sie setzt exakt das um, was spezifiziert ist, inklusive aller Lücken. Das führt zu einem interessanten Effekt: → Architekturfehler werden nicht mehr „verdeckt“, sondern sofort sichtbar und reproduzierbar. Ich habe das im Projekt relativ deutlich gesehen: Der größte Fehler war am Ende kein Bug im Code, sondern ein fehlender Datenfluss bei eigentlich korrekten Komponenten. Das wäre in einem klassischen Team vermutlich länger „mitgeschleppt“ worden. Deshalb sehe ich KI weniger als Ersatz für Entwickler, sondern eher als Verstärker für Architekturqualität: - saubere Spezifikation → sehr gute Ergebnisse - unscharfe Spezifikation → zuverlässig schlechte Ergebnisse Dein Punkt zur Planungsphase passt da perfekt rein. Das Bottleneck verschiebt sich meiner Meinung nach von der Implementierung hin zur Definition von: - Zuständen - Datenflüssen - Invarianten Ich versuche das aktuell über relativ harte Guardrails + Pre-Check-Systeme zu erzwingen. Der Code ist da fast nur noch „Konsequenz der Architektur“. Was mich interessieren würde: Hast du in deinen Projekten Ansätze gesehen, wie man diese Spec-Drift systematisch in den Griff bekommt? Also eher methodisch (z. B. ArchUnit, Contracts, formale Constraints etc.) – unabhängig von KI?Genau das ist für mich auch der entscheidende Punkt. Ich sehe das weniger als Frage „KI vs. Mensch“, sondern als Frage der notwendigen Präzision in der Architektur. Bei menschlichen Entwicklern können unklare oder unvollständige Vorgaben oft durch Erfahrung und Kreativität ausgeglichen werden. Das System bleibt trotzdem funktionsfähig. Bei KI funktioniert das nicht. Sie setzt exakt das um, was spezifiziert ist – inklusive aller Lücken. Für mich führt das zu der Konsequenz, dass Architektur und Spezifikation deutlich präziser und strukturierter gedacht werden müssen, wenn man KI ernsthaft einsetzen will. Mein Ansatz mit dem AXIOM-Projekt geht genau in diese Richtung: Systeme so zu entwerfen, dass Zustände, Datenflüsse und Abhängigkeiten möglichst deterministisch und nachvollziehbar bleiben, anstatt sich auf implizite Annahmen zu verlassen. In dem Sinne passt der Vergleich eigentlich sehr gut – nur dass die fehlende „Kompensation“ der KI die Schwächen der Architektur deutlich sichtbarer macht.Kurzes Update zum Projekt – inzwischen ist einiges passiert. Ich bin mittlerweile aus der reinen Experimentphase raus und habe das System einmal komplett refaktorisiert und stabilisiert. ## 🔧 Stand aktuell Die komplette Pipeline ist jetzt durchgängig: SQLite → Core → UI → Rendering Das hatte ich am Anfang tatsächlich nicht sauber geschlossen – das System hatte einen klassischen "Silent Failure": → Daten waren korrekt vorhanden → wurden aber nicht dargestellt Am Ende war das kein Bug, sondern ein Architekturproblem. ## 🧠 Wichtigste Änderung: Determinismus Ich habe im Rahmen des Refactorings eine harte Entscheidung getroffen: → vollständiges Verbot von float/double im Core Stattdessen läuft alles über ein eigenes Fixed-Point System auf int64-Basis. Grund: - reproduzierbare Ergebnisse - keine Rundungsfehler - plattformunabhängig ## 🧱 Architektur Ich habe die Struktur jetzt komplett klar gezogen: - Core (C++20, deterministisch, ohne UI) - Mapping Layer (DB → Core) - SQLite (DAO Pattern) - UI (Dear ImGui) - Rendering (Metal) Wichtig: Kein Layer kennt Funktionen eines anderen, die er nicht kennen darf. ## 🔧 Refactoring-Erkenntnis Der spannendste Punkt war ehrlich gesagt: Der größte Fehler im System war kein Code-Fehler, sondern ein fehlender Datenfluss. Das hat man erst gesehen, als alles „eigentlich korrekt“ war. ## 🌍 Ergebnis - Trades werden jetzt korrekt aus SQLite geladen - im Core deterministisch berechnet - im UI dargestellt - und auf der Weltkarte visualisiert ## 🚀 Nächster Schritt - Async DB Worker (kein I/O im UI Thread) - Interaktion auf der Map (Zoom / Selection) - Weiter Richtung Simulation / Constraints statt Logging ## 🧠 Fazit bisher Die eigentliche Schwierigkeit ist nicht: „Kann KI Code schreiben?“ sondern: „Kann man die Architektur so präzise definieren, dass KI gar nicht falsch arbeiten kann?“ Falls Interesse besteht, kann ich gerne nochmal detaillierter auf das Refactoring eingehen – das war tatsächlich der lehrreichste Teil.
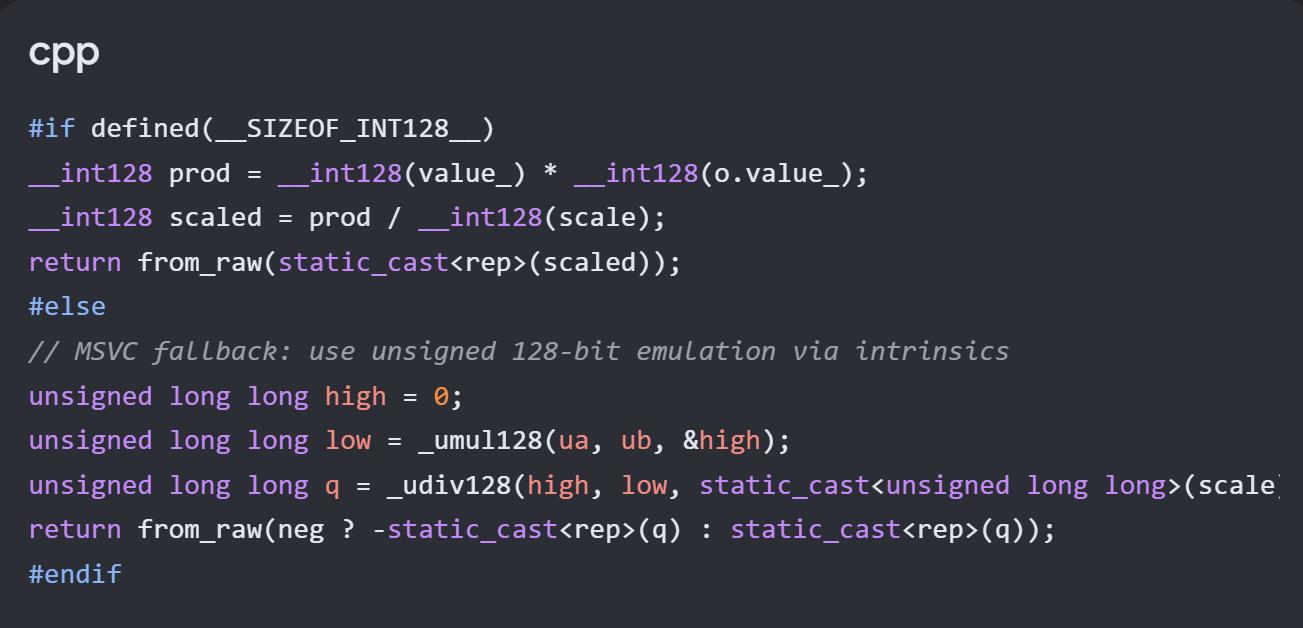
 Kurzes Update dazu: Ich habe die daraus entstandene Architektur-Anpassung inzwischen sauber in das ADR-0004 überführt und versioniert. Konkret wurde dort jetzt explizit festgehalten, dass: __int128 keine valide Grundlage für Cross-Platform-Code ist und alle entsprechenden Operationen über Compiler-Guards bzw. Intrinsics abgesichert werden müssen Das war im ursprünglichen ADR so nicht sauber formuliert und ist erst durch den Pre-Check sichtbar geworden. Für mich bestätigt das aktuell den Ansatz ganz gut: → reale Probleme führen zu architektonischen Präzisierungen, nicht nur zu Code-Fixes.Hallo @Wodar Hospur, guter Punkt – das wirkt auf den ersten Blick tatsächlich wie ein Widerspruch, ist aber im Kern eine bewusste Designentscheidung, die ich gerade aufgrund eines KI‑Prechecks angepasst habe. Zur 64‑bit vs. 128‑bit Frage: Im ADR ist bewusst festgelegt: Persistenz / Datenmodell → int64_t (Fixed Point, skalierte Ganzzahlen) 128‑bit → nur als intermediäre Rechenhilfe (Multiply/Divide), nicht als Data-Type Das Problem ist durch den Pre‑Check jetzt sichtbar geworden: Damit verletze ich mein eigenes Blender-/DNA-Prinzip: Das ist kein Optimierungsproblem, sondern ein architektonischer Regelbruch. Deshalb die Anpassung: 64‑bit bleibt der definierte Datenraum 128‑bit wird nicht mehr als „implizit vorhanden“ angenommen sondern über: Compiler-Guards oder platform-spezifische Intrinsics (_umul128 etc.) explizit behandelt Das ADR ist an der Stelle aktuell noch nicht nachgeführt – das ist genau der Punkt, den dieser Pre‑Check sichtbar gemacht hat.Hallo @hellerKopf , exakt an diesem Punkt schließt sich der Kreis zu meinem neuen Pre-Check-System. Du hast vollkommen recht: Wenn ich den Code genauso mühsam Zeile für Zeile prüfen muss, habe ich zeitlich nichts gewonnen. Genau deshalb zwinge ich die KI, die Beweislast umzukehren und das Konformitäts-Audit vorab selbst zu schreiben. Als menschlicher Architekt lese ich nicht mehr kopflos C++ Code, sondern prüfe primär die Plausibilität der von der KI gelieferten Beweiskette gegen meine Invarianten. Und hier ist der direkte Praxis-Beweis, wie dieses System ein rein menschliches Review schlägt: Ich habe die KI über meine Pipeline das Refactoring der Festkomma-Arithmetik (ADR-0004) in die Sandbox docs/pre-checks/0004-fixed-point-review.md generieren lassen. Beim Überfliegen des von der KI geschriebenen Audits fiel der Blick sofort auf Kapitel 4: „Grenzen und Risiken – Compiler-Unterstützung“. Die KI stellte dort in ihrem eigenen Audit fest: „Implementierung nutzt int128. Wenn der Compiler keine int128-Unterstützung bietet (z. B. MSVC ohne Emulation), schlägt die Compilation fehl.“ Einem menschlichen Junior-Entwickler (und Hand aufs Herz: auch vielen Senioren!) wäre dieser plattformspezifische Fehler beim schnellen Tippen unter macOS niemals aufgefallen. Sie hätten den Code eingecheckt, und das Windows-Build-System wäre Stunden später auf die Nase geflogen. Weil meine Pipeline die KI aber dazu zwingt, ein eigenes Risiko-Audit abzuliefern, wurde diese architektonische Sollbruchstelle sichtbar, bevor auch nur eine einzige Zeile Code live in den Core geflossen ist. Ich habe die KI aufgrund ihres eigenen Audits nun angewiesen, ein plattformunabhängiges Fallback via Compiler-Guards und x64-Hardware-Intrinsics (_umul128 / _udiv128) für den MSVC-Compiler auf Windows einzubauen, um das Blender-Prinzip (vollkommene OS-Unabhängigkeit) zu wahren. Der Code sieht im Pre-Check für Windows nun so aus: Vollständiger Source ist im Repository
Kurzes Update dazu: Ich habe die daraus entstandene Architektur-Anpassung inzwischen sauber in das ADR-0004 überführt und versioniert. Konkret wurde dort jetzt explizit festgehalten, dass: __int128 keine valide Grundlage für Cross-Platform-Code ist und alle entsprechenden Operationen über Compiler-Guards bzw. Intrinsics abgesichert werden müssen Das war im ursprünglichen ADR so nicht sauber formuliert und ist erst durch den Pre-Check sichtbar geworden. Für mich bestätigt das aktuell den Ansatz ganz gut: → reale Probleme führen zu architektonischen Präzisierungen, nicht nur zu Code-Fixes.Hallo @Wodar Hospur, guter Punkt – das wirkt auf den ersten Blick tatsächlich wie ein Widerspruch, ist aber im Kern eine bewusste Designentscheidung, die ich gerade aufgrund eines KI‑Prechecks angepasst habe. Zur 64‑bit vs. 128‑bit Frage: Im ADR ist bewusst festgelegt: Persistenz / Datenmodell → int64_t (Fixed Point, skalierte Ganzzahlen) 128‑bit → nur als intermediäre Rechenhilfe (Multiply/Divide), nicht als Data-Type Das Problem ist durch den Pre‑Check jetzt sichtbar geworden: Damit verletze ich mein eigenes Blender-/DNA-Prinzip: Das ist kein Optimierungsproblem, sondern ein architektonischer Regelbruch. Deshalb die Anpassung: 64‑bit bleibt der definierte Datenraum 128‑bit wird nicht mehr als „implizit vorhanden“ angenommen sondern über: Compiler-Guards oder platform-spezifische Intrinsics (_umul128 etc.) explizit behandelt Das ADR ist an der Stelle aktuell noch nicht nachgeführt – das ist genau der Punkt, den dieser Pre‑Check sichtbar gemacht hat.Hallo @hellerKopf , exakt an diesem Punkt schließt sich der Kreis zu meinem neuen Pre-Check-System. Du hast vollkommen recht: Wenn ich den Code genauso mühsam Zeile für Zeile prüfen muss, habe ich zeitlich nichts gewonnen. Genau deshalb zwinge ich die KI, die Beweislast umzukehren und das Konformitäts-Audit vorab selbst zu schreiben. Als menschlicher Architekt lese ich nicht mehr kopflos C++ Code, sondern prüfe primär die Plausibilität der von der KI gelieferten Beweiskette gegen meine Invarianten. Und hier ist der direkte Praxis-Beweis, wie dieses System ein rein menschliches Review schlägt: Ich habe die KI über meine Pipeline das Refactoring der Festkomma-Arithmetik (ADR-0004) in die Sandbox docs/pre-checks/0004-fixed-point-review.md generieren lassen. Beim Überfliegen des von der KI geschriebenen Audits fiel der Blick sofort auf Kapitel 4: „Grenzen und Risiken – Compiler-Unterstützung“. Die KI stellte dort in ihrem eigenen Audit fest: „Implementierung nutzt int128. Wenn der Compiler keine int128-Unterstützung bietet (z. B. MSVC ohne Emulation), schlägt die Compilation fehl.“ Einem menschlichen Junior-Entwickler (und Hand aufs Herz: auch vielen Senioren!) wäre dieser plattformspezifische Fehler beim schnellen Tippen unter macOS niemals aufgefallen. Sie hätten den Code eingecheckt, und das Windows-Build-System wäre Stunden später auf die Nase geflogen. Weil meine Pipeline die KI aber dazu zwingt, ein eigenes Risiko-Audit abzuliefern, wurde diese architektonische Sollbruchstelle sichtbar, bevor auch nur eine einzige Zeile Code live in den Core geflossen ist. Ich habe die KI aufgrund ihres eigenen Audits nun angewiesen, ein plattformunabhängiges Fallback via Compiler-Guards und x64-Hardware-Intrinsics (_umul128 / _udiv128) für den MSVC-Compiler auf Windows einzubauen, um das Blender-Prinzip (vollkommene OS-Unabhängigkeit) zu wahren. Der Code sieht im Pre-Check für Windows nun so aus: Vollständiger Source ist im Repository