Community durchsuchen
Zeige Ergebnisse für die Tags "'datenbanken'".
10 Ergebnisse gefunden
-

Daten aus alter POET-Datenbank (von ca. 1999) herausbekommen
afo erstellte eine Frage in Anwendungsentwickler und Programmierer
Hallo zusammen, ich weiß das ist eine sehr spezielle Frage, aber vielleicht hat einer der alten Hasen da noch Berührungspunkte. Ich müßte Daten aus einer alten POET (wurde später zu FastObjects) Datenbank (Server von ca 1997-1999) rausbekommen. Das läuft bei einem Kunden. Er hat den DB-Server und das Anwendungsprogramm, was aber leider keine Exportmöglichkeiten bietet. Hat hier jemand noch mit POET zu tun und kennt eventuell ein Exporttool, ODBC-Treiber, Entwicklertools, oder ähnliches? -

ER-Modell richtig oder falsch?
Planl0s erstellte eine Frage in Anwendungsentwickler und Programmierer
Wir haben folgende Aufgabenstellung erhalten: "Die Firma „Bugs“ fertigt verschiedene Geräte. Für die betriebliche Organisation dieser Firma soll eine relationale Datenbank eingesetzt werden. Dabei gilt folgendes: Jedes Bauteil, das verwendet wird, hat eine eindeutige Nummer und eine Bezeichnung, die allerdings für mehrere verschiedene Bauteile gleich sein kann. Von jedem Teil wird außerdem der Name des Herstellers, der Einkaufspreis pro Stück und der am Lager vorhandene Vorrat gespeichert. Jedes herzustellende Gerät hat eine eindeutige Bezeichnung. Auch von jedem schon gefertigten Gerätetyp soll der aktuelle Lagerbestand gespeichert werden, ebenso wie der Verkaufspreis des Gerätes. In unserem fiktiven Betrieb gilt die Regelung, dass Maschinen, die mehr als 1000,- EUR kosten, unentgeltlich an die Kunden ausgeliefert werden; für Geräte, die weniger kosten, ist zusätzlich zum Preis eine gerätespezifische Anliefergebühr zu entrichten. In der Datenbank ist ebenfalls zu speichern, welche Bauteile für welche Geräte benötigt werden. Es gibt Bauteile, die für mehrere Geräte verwendet werden. Von jedem Kunden wird der Name, die Adresse und die Branche gespeichert. Es kann verschiedene Kunden mit demselben Namen oder derselben Adresse geben. Außerdem ist zu jedem Kunden vermerkt, wer aus unserer Firma für die entsprechende Kundenbetreuung zuständig ist. Natürlich ist auch zu speichern, welche Kunden mit welchen Geräten beliefert werden. Es kann sein, dass gewissen Kunden für bestimmte Geräte Sonderkonditionen eingeräumt worden sind, dies soll ggf. ebenfalls in der Datenbank vermerkt werden." (wollte einen Spoiler nutzen, um die Aufgabenstellung zu verstecken, aber scheint leider nicht zu funktionieren) Dazu soll ein ER-Modell erstellt werden. Nun bin ich mir unsicher, ob meins ausreichend ist, oder ob ich etwas vergessen habe. Könnte da vielleicht mal jemand drüberschauen? Grüße und noch einen schönen Tag 😅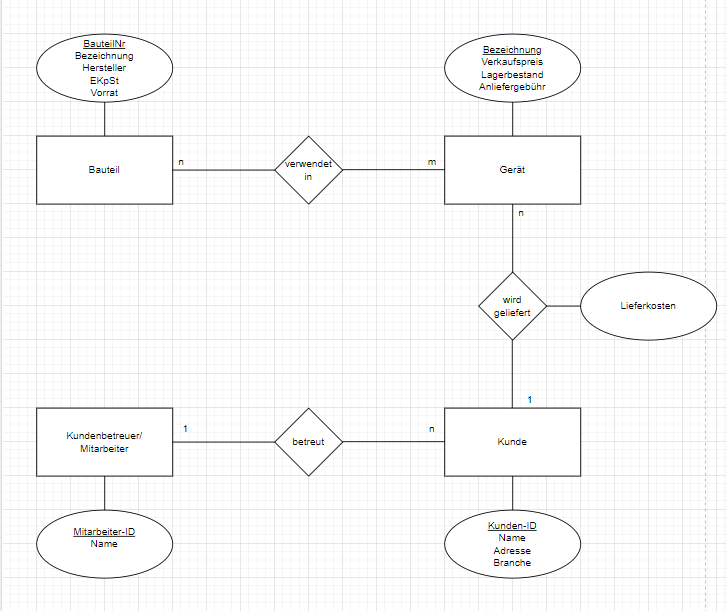
-
Guten Tag liebe Leute, ich hätte ein kurzes anliegen ich bin noch ein noob in dem Thema also bitte macht mich nicht fertig Habe eine .backup Datei einer DB von einem Neukunden bekommen und muss teile aus der DB exportieren. Das problem dabei ist ich kann die Datei nicht auslesen. PHPmyAdmin lädt die Datei nicht hoch und DBForge akzeptiert den Dateitypen nicht (aber auch ganz stupide Dateitypnamen auf .sql umgeändert und kriege folgenden fehler) Stehe leicht aufm schlauch kann einer vllt einen Tipp geben ??
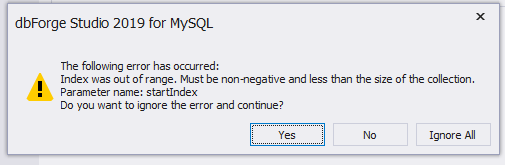
-
 Hallo zusammen, ich habe Anfang nächster Woche einen Termin fürs Probearbeiten für ca. 3 Stunden für die Ausbildung zum Fachinformatiker für Daten- und Prozessanalyse noch in diesem Jahre und wollte fragen, wie ich mich darauf vorbereiten kann. Der zugewiesene Ausbildungstutor ist Datenbankentwickler. Dabei soll ich das Unternehmen und ihre Arbeitsweise kennenlernen. Zudem werden sie mir kleine Arbeitsaufgaben geben, damit ich einschätzen kann, welche fachlichen Aufgaben ich in der Ausbildung erwarten könnte, gleichzeitig erhält das Unternehmen einen ersten Eindruck davon, welche Vorkenntnisse ich schon möglicherweise mitbringe. Ich habe Grundkenntnisse in Python und ein bisschen Java sowie Webentwicklung, kenne mich aber nicht mit SQL aus. Laut den Stellenangebote des Unternehmen habe ich herausgefunden, dass das Unternehmen mit C#, Python, mySQL, postegreSQL und MS SQL Server arbeitet. Was könnten mich bei den kleinen Arbeitsaufgaben erwarten? Sollte ich eher auf das Programmieren an sich aneignen oder lieber mir soviel Halbwissen über Datenbanken aneignen wie möglich? Das Unternehmen ist ein mittelständischer Softwarehersteller für Marktanalysen in der Automobilbranche. Für Ratschläge und Tipps wäre ich euch echt dankbar.
Hallo zusammen, ich habe Anfang nächster Woche einen Termin fürs Probearbeiten für ca. 3 Stunden für die Ausbildung zum Fachinformatiker für Daten- und Prozessanalyse noch in diesem Jahre und wollte fragen, wie ich mich darauf vorbereiten kann. Der zugewiesene Ausbildungstutor ist Datenbankentwickler. Dabei soll ich das Unternehmen und ihre Arbeitsweise kennenlernen. Zudem werden sie mir kleine Arbeitsaufgaben geben, damit ich einschätzen kann, welche fachlichen Aufgaben ich in der Ausbildung erwarten könnte, gleichzeitig erhält das Unternehmen einen ersten Eindruck davon, welche Vorkenntnisse ich schon möglicherweise mitbringe. Ich habe Grundkenntnisse in Python und ein bisschen Java sowie Webentwicklung, kenne mich aber nicht mit SQL aus. Laut den Stellenangebote des Unternehmen habe ich herausgefunden, dass das Unternehmen mit C#, Python, mySQL, postegreSQL und MS SQL Server arbeitet. Was könnten mich bei den kleinen Arbeitsaufgaben erwarten? Sollte ich eher auf das Programmieren an sich aneignen oder lieber mir soviel Halbwissen über Datenbanken aneignen wie möglich? Das Unternehmen ist ein mittelständischer Softwarehersteller für Marktanalysen in der Automobilbranche. Für Ratschläge und Tipps wäre ich euch echt dankbar. -
Hey! Ich würde gerne alle Datenbanken außer Datenbank x auf Server a in eine Datei speichern. Dafür habe ich bislang das hier geschrieben: (Passwort ist nur auf einem testserver so der aus dem internet nicht erreichbar ist ^^ ) - name: get all db command: mysql -u root -p=root -Bse 'show databases' register: database_all - name: set db set_fact: db_all="{{ database_all.stdout_lines }}" - name: get all dbs that should be backuped set_fact: database_different="{{ db_all | difference("database_test") || list }}" - name: dump db shell: "/usr/bin/mysqldump -Q --single-transaction -u root -h localhost -p=root database_different | /bin/gzip -9 > /root/mysql_backups/file.gz" - name: debug db #war nur ein test um zu schauen ob alles richtig ist debug: msg: "{{ db_all }}" Bei der dritten Task kommt nun folgende Fehlermeldung: "template error while templating string: expected token 'name', got '|'. String: {{ db_all | difference(\"database_test\") || list }}" Soweit ich das verstehe, scheint db_all keine Liste zu sein? Und irgendwie befürchte ich auch, dass ich bei difference nicht einfach einen String mit dem Namen von Datenbank x angeben kann, richtig? Wie löse ich das dann? Desweiteren ist mir gerade aufgefallen, dass ich die Variable database_different gar nicht so in den shell Befehl packen kann, sondern den Befehl dann erst zwischenspeichern muss damit das geht.... oder? Sind viele Fragen, ich weiß... Tut mir leid ^^ Trotzdem hoffe ich auf ein bisschen Hilfe. Sitze da nun schon Stunden dran und komme nicht vorran. Danke euch!
-
Hallo , ich habe mein Bachelor als Software Ingenieur im Iran absolviert und danach habe ich fast 8 Jahre in einer IT Abteilung bei einer Bank als Datenbankentwickler gearbeitet. seit 2015 bin ich in Deutschland. Innerhalb ersten 2 Jahren dürfte ich werde arbeiten noch an einem Deutschkurs teilnehmen (wegen meinem Aufenthaltserlaubnis). Dann habe ich meine Deutschkenntnisse bis C1 ausgebaut und danach habe ich nach einem Coaching eine Weiterbildung im Bereich Java-Programmierung durchgeführt, die fast 60 Werktage gedauert hat. (Bis Ende Februar 2020). aber konnte ich wegen den folgenden Gründen bis heute keinen passenden Job finden : seit fast 6 Jahre habe ich im Bereich Datenbanken nicht mehr gearbeitet , deswegen bin nicht Up-to-date und wenn ich ehrlich bin, wenn man paar Jahren nicht mehr arbeitet, vergiss man viele Themen und außerdem haben viele Softwares sich geändert mit neue Versionen und damit habe ich keine Ahnung. beispielsweise habe ich mit Oracle 8, 9 , 10 , 11 gearbeitet und dann kamm 12, 13 , 19 und jetzt 21. ich habe nur eine Weiterbildung im Bereich Java erledigt und innerhalb 2 , 3 Monaten kann man nur Theoretisch lernen und habe gar keine praktische Erfahrung und keine Firma nimmt jemand Ohne praktische Erfahrungen. ich weiß nicht, vielleicht sollte ich statt Java eine Oracle Datenbank Weiterbildung durchgeführt habe, um mit meiner Erfahrungen geeignet zu sein??!!! ich bitte euch jetzt um eine Hilfe. wie kann ich mich wieder in den IT-Markt rein??? LG Ali
-
Hallo Freunde, ich habe diese Woche erfolgreich meinen Abschluss als FISI erworben und wurde von meinem AG übernommen. Als Azubi habe ich größtenteils normale FISI Aufgaben erledigt, wie z.b. Drucker und PCs installieren. Jetzt soll mein Arbeitsalltag allerdings zu einem großen Teil aus der Pflege unserer Oracle Datenbanken bestehen. Ich hab damit natürlich null Erfahrung und wir haben zurzeit auch niemanden im Unternehmen der sich damit auskennt. Mein Chef hat mir gesagt, ich soll ihm einen Plan vorlegen, welche Schulungen ich besuchen möchte. Geld spielt erstmal keine Rolle. Allerdings sollen das nicht nur Schulungen sein, wo man im nachhinein ein normales Teilnehmerzertifikat bekommt, sondern vllt auch noch eine Prüfung ablegen muss. Im Internet findet man ja haufenweise Angebote für Weiterbildungen. Mit welchen Anbietern habt ihr gute Erfahrungen gemacht oder welche könnt ihr empfehlen? Und welche Schulungen sind für mich als Neuling überhaupt geeignet? Oracle bietet ja selber das "Oracle Certification Program" an, welches aber relativ schwierig sein soll. Ich hoffe ihr könnt mir weiterhelfen. Vielen Dank schonmal!
-
Hallo Zusammen, Ist es möglich, einen ALTER DATABASE Befehl über alle auf der Instanz vorhandenen Datenbanken durchzuführen? Hintergrund meiner Frage: Ich möchte alle Data- und Logfiles meiner Datenbanken auf die aktuellen Settings zu maxsize und AutoGrow(%) auslesen. --> Diese Abfrage habe ich bereits und es klappt auch. Anschließend möchte ich alle Log- und Datafiles auf einen festgelegten Wert bringen (Log = 10MB / Datafile = 100MB). Das heißt, wenn ich richtig überlege, muss ich eine ALTER DATABASE-Abfrage schreiben, welche alle DBs bzw deren Data- und Logfiles anfasst (ich habe auf die Instanz vollen und uneingeschränkten Zugriff) und die Werte entsprechend abändert. Ist so etwas möglich? LG
-
Hallo zusammen, ich beschäftige mich gerade mit Datenbanken. Ich habe nun mit den Befehlen "create database datenbankname" und "create table tabellenname" eine Datenbank mit einigen Tabellen angelegt. Danach habe ich nun versucht die Tabellen mit dem Befehl "insert into tabellenname values(...);" einzufügen. Beispiel: 1. Ich habe eine Tabelle "Kunden" mit den Attributen "ID", "Name", "Vorname" und "Strasse". ID ist vom Datentyp Integer und die anderen drei Attribiute sind vom Datentyp Varchar. Befehl zum Einfügen von Daten: INSERT INTO Kunden VALUES(01, 'Mustermann', 'Max', 'Musterstrasse 1'); 2. Ich habe eine Tabelle "Auto" mit den Attributen "ID", "Kunde", "Name", "Kennzeichen". ID ist wieder vom Typ Integer, Kunde ebenso (referenziert auf die ID in der Kundentabelle als Fremdschlüssel) und Name sowie Kennzeichen sind wieder vom Typ Varchar. Befehl zum Einfügen von Daten: INSERT INTO Auto VALUES(01, 01, 'VW Golf', 'XY Z 99'); Beide Tabellen befinden sich logischerweise in derselben Datenbank. Nun tritt folgendes Problem auf: Ich führe die Abfrage zum Einfügen der Daten in die Tabellen ein (mit mehreren Datensätzen, nicht nur einem). Die Tabelle Kunden wird wie angegeben gefüllt und ich kann sie mir danach problem anschauen und weitere Abfragen auf ihr ausführen. Bei der Tabelle Auto bekomme ich jedoch folgende Fehlermeldung und sie wird nicht gefüllt: "Conversion failed when converting the varchar value 'XY-Z99' to data type int." Wieso wird hier nun versucht varchar in int umzuwandeln? Ich gebe nichts dergleichen an? Ich dachte erst, es liegt vielleicht daran, dass Buchstaben und Zahlen gemixt sind, aber das ist ja bei dem Attribut "Strasse" in der Tabelle "Kunden" ebenfalls der Fall und da gibt es keine Probleme. Muss ich für solche Fälle vielleicht einen anderen Datentyp wählen oder irgendwas zusätzlich konvertieren? Das Attribut kommt nur in dieser Tabelle vor und wird sonst nirgendwo referenziert oder sonstiges. Ich hoffe, jemand kann mir weiterhelfen...:) Danke im Voraus!
-
 Hallo zusammen, ich beschäftige ich mich zur Zeit sehr viel mit oben genannten aus dem Bereich Business Intelligence. Hierbei suche schon lange nach einer Referenzarchitektur (Abbildung/Zeichnung) der In-Memory Technologie im Internet habe aber bis jetzt leider noch keins gefunden. Wäre toll wenn ihr mir vielleicht weiterhelfen könntet. Auch habe ich noch ein paar Fragen zur In-Memory Technologie 1. Bei klassischen DWH - Ansatz werden die Daten mit Hilfe des ETL (Extraktion, Transformation,Load) Prozesses vergleichbar gemacht. Wie funktioniert das bei der In-Memory Technologie? 2. Welche Datenmenge wird ursprünglich bei dieser Technik im Ram gehalten/geschrieben? 3.Wie hoch ist der Kostenunterschied dieser beiden Ansätzen in einem KMU durchschnittlich? 4. gute detailierte Erklärung/Artikel, des In-Memory Technologie Ansatzes (deutsch wenn möglich) Wenn ihr mir bei der ein oder anderen Frage weiterhelfen könntet wäre ich echt froh:) Vielen Dank für ihre Mühe und Hilfe im Vorraus:)
Hallo zusammen, ich beschäftige ich mich zur Zeit sehr viel mit oben genannten aus dem Bereich Business Intelligence. Hierbei suche schon lange nach einer Referenzarchitektur (Abbildung/Zeichnung) der In-Memory Technologie im Internet habe aber bis jetzt leider noch keins gefunden. Wäre toll wenn ihr mir vielleicht weiterhelfen könntet. Auch habe ich noch ein paar Fragen zur In-Memory Technologie 1. Bei klassischen DWH - Ansatz werden die Daten mit Hilfe des ETL (Extraktion, Transformation,Load) Prozesses vergleichbar gemacht. Wie funktioniert das bei der In-Memory Technologie? 2. Welche Datenmenge wird ursprünglich bei dieser Technik im Ram gehalten/geschrieben? 3.Wie hoch ist der Kostenunterschied dieser beiden Ansätzen in einem KMU durchschnittlich? 4. gute detailierte Erklärung/Artikel, des In-Memory Technologie Ansatzes (deutsch wenn möglich) Wenn ihr mir bei der ein oder anderen Frage weiterhelfen könntet wäre ich echt froh:) Vielen Dank für ihre Mühe und Hilfe im Vorraus:)








