

_n4p_
-
Gesamte Inhalte
1338 -
Benutzer seit
-
Letzter Besuch
-
Tagessiege
15
Inhaltstyp
Profile
Forum
Downloads
Kalender
Blogs
Shop
Beiträge von _n4p_
-
-
vor 19 Minuten schrieb SophieFischer:
Es gibt /r:0 /w:0 - für was steht dies?
/r:<n>Specifies the number of retries on failed copies. The default value of n is 1,000,000 (one million retries).
/w:<n>Specifies the wait time between retries, in seconds. The default value of n is 30 (wait time 30 seconds).
vor 22 Minuten schrieb SophieFischer:Ich möchte einen Ordner "Test" von Laufwerk 😄 auf Laufwerk E: kopieren. Der Ordner "Test" muss im Laufwerk E: erscheinen. Es dürfen aber keine Dateien von E: gelöscht werden dadurch.
das ist das standardverhalten von robocopy oder überseh ich hier etwas?
-
vor 21 Stunden schrieb HJST1979:
Es geht darum, dass eine Meldung über z.B. einen Telefonausfall an alle IT-Mitarbeiter verteilt wird
dafür benachrichtigt unser check_mk verschiedene channel in mattermost. ein channel für kritisches, einer für den rest. wenn man das richtig einstellt werden auch nur die mitarbeiter per @ erwähnt die für das problem zuständig sind.
das monitoring könnte auch tickets in jira o.ä. erstellen ..
-
Wenn dein Unternehmen dich in LoC misst, such dir schnell ein anderes Unternehmen.
Wenn du aber für ein vermeintlich (oder für außenstehende) einfaches Problem Monate statt Tage/Wochen benötigst, solltest du das erklären können.
-
vor 50 Minuten schrieb Crash2001:
persönliche Daten auf einem öffentlichen Laufwerk
und ihr dürft die Arbeitsplätze und verbundene Infrastruktur für privates Nutzen?
-
1. - es geht um dich. es hilft dir nicht weiter wenn ich hier diverse Tools aufzähle. Google nach "Desktopmanagment" schau dir die an welche Funktionen die Webseiten der Hersteller bewerben. Erkläre im Gespräch, das du noch nicht die Gelegenheit hattest sowas zu nutzen aber du hast von XY und Z gelesen.
2. - du hast aber schon mal n PC neu installiert? wobei die frage schon seltsam ist. Die Hardware, die Software inkl. OS, beides? Worauf achtest du denn dabei?
3. - siehe 1
4., 5., 6. - Google
7. - was für mich funktioniert kannst du total bekloppt finden
8. - Schockstarre ist hier die falsche Antwort. Die Frage hat auch nichts mit deiner schlechten Umschulung zu tun. Und wenn dir hier nix einfällt, weiß ich auch nicht.
9. - Ich denke du warst im First Level? Kollegen sind auch nur Kunden mit mehr Geduld.
10. - Wann und zu welchem Zweck nutzt man denn VPN? Wieder ne Frage für Google.
11. - das reicht so von: Kein Mittagessen, weil das 11 Uhr Meeting bis 13:50 ging und 14:00 der nächste Kunde wartet.
bis: Klar verzichte ich 3 Monate auf Gehalt wenn es der Firma grad schlecht geht, aber schönes neues Auto Chef.12. - siehe 7
---------------
nachdem ich nun deine Hausaufgaben gemacht hab noch ein gut gemeinter rat. nach dem was du im praktikum gemacht hast, dürftest du 10 der Fragen nicht ernsthaft stellen. wenn dir das wissen fehlt, such dir ne firma bei der du nochmal 2-3 monate praktikum machen kannst. am besten eine wo du einem mitarbeiter hinterherlaufen darfst. alternativ gibt es zu jedem thema etwas im internet zu finden. aber vorgekaute antworten bringen dich nicht weiter.
ZitatIch gehe einfach mal davon aus, dass Du nicht absolut teilnahmlos auf dem Stuhl gesessen und ins Leere gestarrt hast...
solche Kandidaten gibt es aber wirklich ...
-
Prinzipiell würde ich auch sagen das 1TB richtig ist. Man könnte in dem NAS natürlich 2 Volumes je 2x1TB anlegen. Aber das würde ich aus der Aufgabe auch nicht herauslesen.
vor 2 Minuten schrieb allesweg:Wenn man ganz streng ist, geht RAID 1 nur mit 2 Platten
das scheint controller abhängig zu sein.
-
oben Zehner darunter einfach durchnummeriert
Zitat0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
Fett ist also die 12 und kursiv die 24.
-
WOW, Nostalgieschnipser .. dafür muss man aber tief graben ..
ZitatIt is useful to preserve and extend the interpretation of these special addresses in subnetted networks. This means the values of all zeros and all ones in the subnet field should not be assigned to actual (physical) subnets.
RFC950, August 1985
Das wurde zwar tatsächlich immer noch nicht abgelöst, nach CIDR von 1993 (RFC1518,...) ist das aber praktisch nicht mehr relevant.
@ld7 tu dir selbst einen Gefallen und schau keine derart alten Prüfungen an. Die Antwort war damals veraltet und ist es heute noch mehr. Derart alte Routing Protokolle dürften nicht mehr rumlaufen.
-
vor 6 Stunden schrieb Whiz-zarD:
Und wie lange hat Boston Dynamics gebraucht, dieses Video zu produzieren?
keine Ahnung. Die Choreographie ist sicher "handgeklöppelt". Wenn man aber bedenkt das Altas vor ein paar Jahren quasi aus dem Stand umfallen konnte, würde ich sagen das man hier eine Entwicklung sehen kann.
-
also zunächst mal, stand der kaufbaren technik ist spot
meiner meinung nach ist das auch der sinnvollere weg, auch wenn atlas mittlerweile tanzen kann.
-
vor 26 Minuten schrieb el_pollo_diablo:
Was sich mir nicht wirklich erschliesst ist, wie man das Sollkonzept offener beschreiben könnte und weshalb es vorentschieden klingt?
weil da die Lösung schon fertig beschrieben wird. Die Lösung soll aber im Projekt gefunden werden.
Hier am Beispiel:
* Warum werden es 3 Server im Cluster?
* Warum überhaupt ein Cluster?
* Gäbe es Alternativen zu MySQL/MariaDB?-------------
mal so inhaltlich:
Am 1.3.2021 um 12:55 schrieb jabafe:klassische Replikationsmethoden [..] mysqldump und restore
was? Welche echten Replikationsmethoden wurden denn schon getestet?
Zu den 3 Servern: Sind das 3 Datenbankserver? was ist mit Load-Balancing und Clustermanagment?
-
vor 2 Stunden schrieb Scrappy Coco:
Bei Ausfall eines Steuerungsrechners würde eine Produktionsmaschine noch etwa 30 Minuten weiterlaufen
vor 2 Stunden schrieb Scrappy Coco:Ersatzrechner nach Rücksicherung in unter 30 Minuten bereitstehen würde.
Jetzt hab ich es verstanden, wenn der Steuerungsrechner ausfällt, hat man 30 Minuten Zeit sonst ist die Maschine die dranhängt 2 Tage aus. Das war mir beim Lesen vom Eingangspost nicht klar. Ich hatte es so verstanden, das die Maschine in jedem Fall nach 30 Minuten ausgeht. Dann ist mein Einwand von oben natürlich auch falsch
")
- Scrappy Coco reagierte darauf
-
 1
1
-
was gibt es denn da nicht zu verstehen?
vor 17 Minuten schrieb Scrappy Coco:der Entscheidungsraum ist im Projektantrag nicht ausreichend dargestellt und entsprechend zu ergänzen.
Welche Entscheidungen triffst du im Projekt? der Antrag liest sich als sei schon alles entschieden und du arbeitest nur noch einen Arbeitsauftrag ab.
vor 19 Minuten schrieb Scrappy Coco:Der Server wird in zwei virtualisierte Sicherungsserver aufgeteilt, welche jeweils ein RAID-6-Volume als Sicherungsziel erhalten.
Es ist sogar sehr detailliert vorgegeben .. warum auch immer das eine gute Idee ist
vor 21 Minuten schrieb Scrappy Coco:Die Projektphasen sind hinsichtlich der Entscheidungen zu überarbeiten und zu ergänzen.
4 Stunden Planung und 13 Stunden Umsetzung und davon installierst du 5 Stunden Software X auf irgendwelchen Clients. Das Verhältnis passt hier einfach nicht.
vor 23 Minuten schrieb Scrappy Coco:Die Kosten-/Nutzenanalyse ist aus der Projektbeschreibung nicht ausreichend dargestellt und entsprechend zu ergänzen.
In der Projektbeschreibung sehe ich auch nichts diesbezüglich. Gut in der Zeitplanung ist dafür ne Stunde vorgesehen.
-----------------
Allgemein: Das Problem ist das der/die Steuerungsrechner ausfallen können. Wie genau verhindert ein Backup das der Steuerungsrechner in Flammen aufgeht?
vor 28 Minuten schrieb Scrappy Coco:Bei Ausfall eines Steuerungsrechners würde eine Produktionsmaschine noch etwa 30 Minuten weiterlaufen und zwei Tage bis zur vollständigen Wiederinbetriebnahme benötigen.
Es dauert 2 Tage die Software wieder auf einem neuen Steuerungsrechner zu installieren? Oder braucht die Maschine 2 Tage für die Inbetriebnahme nachdem der neue Rechner angeschlossen wurde?
-
wenn jetzt jeder hier einfach seine Lösung postet, mach ich das halt auch
def count_value(arr, value): return len([x for x in arr if x == value]) print(count_value([7,5,3,2,4,5,2,4,5,6,3,1,3,6,8,9,6], 4)) -> 2 def count_other(arr, value): new = [] for x in arr: if x == value: new.append(x) return len(new) print(count_other([7,5,3,2,4,5,2,4,5,6,3,1,3,6,8,9,6], 4)) -> 2
Beide Funktionen machen inhaltlich das gleiche. Es wird eine neue Liste angelegt die nur noch die gesuchten Werte enthält, die Funktion gibt dann jeweils die Länge der Liste (Anzahl der Elemente) zurück.
vor 14 Stunden schrieb clowndown:Wäre echt nett wenn jemand mir erklären könnte wie es funktioniert.
Wie sahen denn deine Überlegungen zu dem Problem aus?
-
Also abgesehen davon das es den Vorschlag schon gab ...
Am 18.2.2021 um 15:22 schrieb Maniska:Und was machst du bei neuen Geräten für Bestandsuser?
?
-
Mir ist ernsthaft nicht klar wohin du mit der Diskussion möchtest. Ob man seinen DevOps-Engineer nun aus der Entwickler oder der Admin-Ecke heraus aufbaut ist recht egal. In beiden Fällen muss die Person Dinge lernen die nicht ursprünglich zu ihrem Aufgabenbereich gehörten. Aus der FiSi Richtung wäre es meiner Meinung nach einfacher, da das Bereitstellen von Infrastruktur sowieso in diesen Aufgabenbereich gehört und programmieren auch Inhalt der Ausbildung ist. Warum müssen sich deiner Meinung nach Entwickler mit CICD und Docker herumschlagen statt der FISIs?
Das DevOps Paradigma nimmt niemandem irgendwelche Aufgaben weg. Das kommt wohl auf die Umsetzung an. Eventuell liegt das bei euch ja daran das ihr 80 Entwickler und 5 Systemintegratoren habt. Wäre es möglich das die Systemintegratoren schon genug andere Aufgaben haben?
vor 3 Stunden schrieb Schnuggenfuggler:paar Entwickler als ausgewiesene DevOps-Spezialisten auch für die [..] DevOps-Infrastruktur verantwortlich.
Wie sieht das aus? Was ist denn DevOps-Infrastruktur? Es klingt als wären da 10 Leute denen das Managment gesagt hat: "Wir machen ab morgen DevOps" und die betreiben jetzt git, Jenkins, Jira und Docker weil sie gehört haben das das zu DevOps gehört. DevOps ist kein Werkzeug DevOps ist die Art der Zusammenarbeit.
vor 4 Stunden schrieb Schnuggenfuggler:Im Alltag liegt es aber bei jedem Entwickler selbst [..] ob [..] und [..] wie er sie benutzt
Ähm .. und DAS funktioniert? Es gibt also einen Prozess der aufgebaut wurde um DevOps umzusetzen (wie auch immer der aussieht) aber der Entwickler entscheidet ob er sich daran hält? Gegen wie viele der 5 Prinzipien von DevOps (Culture, Automation, Lean, Measurement, Sharing) verstoßt ihr denn so insgesamt?
-
vor 4 Stunden schrieb MarcoDrost:
Dies wird u.a. damit begründet, dass sich ausgebildete Fachinformatiker durch die tägliche Mitarbeit in einem Unternehmen, sich mehr Praxisnähe auszeichnen. Umschüler erwerben ihre praktischen Kenntnisse "nur" durch Praktika.
Das hängt vermutlich sehr stark vom Bildungsträger ab. Bei uns lief damals quasi alles praktisch ab. Vom einfachen erstellen einer kleinen Domäne mit Clients in VMs bis zu Forests inklusive Vertrauensstellungen und Zertifizierungsstellen über den gesamten Klassenraum. Ich weiß aber auch von anderen Einrichtungen wo derartiges nicht mal der Dozent zeigen könnte selbst wenn die Hardware dafür getaugt hätte.
-
vor 58 Minuten schrieb allesweg:
Wenn angemerkt wird, dass etwas nicht Bestandteil ist, wird es üblicherweise als Bestandteil gewünscht/gefordert.
du meinst also die Kundendoku soll noch zusätzlich mit rein?
-
Klare Anweisung? na vielleicht. Aber in dem Antrag lese ich nichts von Kundendoku und warum zwingt der PA zum Monitoring via SNMP?
-
vor 12 Minuten schrieb theloc866:
Ich weiß nicht, ob das relevant ist, aber ich sehe eigentlich immer im Aktivitätsmonitor diesen Prozess:
kannste ignorieren, der gehört da hin. Der Prozess holt wohl die Daten für die hübschen Charts im Aktivitätsmonitor. Du kannst auch sehen das der Prozess die tempdb nutzt. Du kannst in der Ansicht auch nach Datenbanken filtern.
master, msdb und tempdb kannst du normalerweise ignorieren.
-
vor 1 Stunde schrieb Maniska:
War es beim SQL Server nicht so, dass der sich RAM krallt, und den erst wieder frei gibt (auch wenn er ihn nicht braucht) wenn ein anderer Prozess nett fragt?
richtig
ich hatte es eigentlich so verstanden das der SQL Server in einer anderen VM läuft. Auf dem Bild sehe ich auch keinen in der Prozessliste. Und bei der Sortierung sollte er recht weit oben dabei sein.
In einem Artikel zu "Problemen" mit dem GarbageCollector im ASP.NET wird empfohlen ein Auge auf folgende Werte zu haben
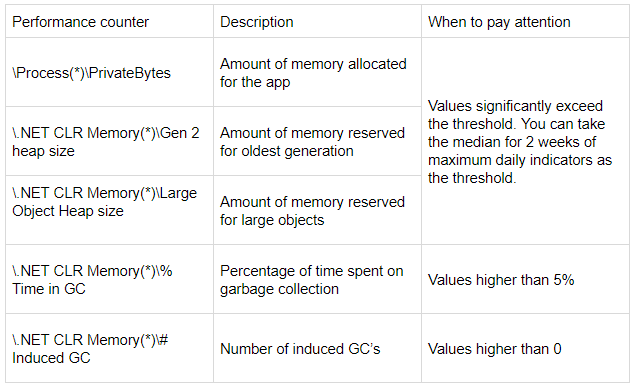
-
vor 3 Minuten schrieb theloc866:
was an den Queries so komplex ist.
dafür kannst du dir den ausführungsplan anzeigen lassen. Entweder per rechtsklick auf die abfrage selbst, oder du kopierst die abfrage aus den details des prozesses. den prozess selbst kannst du dir auch mit dem sql profiler ansehen.
-
vor 7 Stunden schrieb theloc866:
Gibt es Möglichkeiten, dass genauer herauszufinden?
da gibt es hier etwas lesestoff: https://stackify.com/w3wp-high-cpu-usage/
Geht die last irgendwann von selbst runter?
um deinen aufwand mit dem problem zu reduzieren kannst du den AppPool automatisch neu starten lassen.
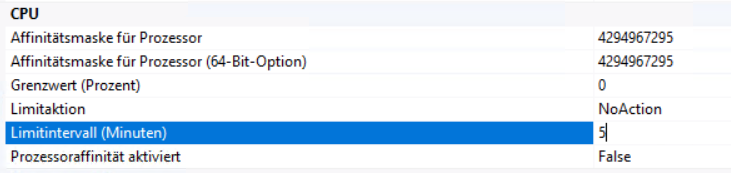
Das findest du unter den erweiterten Einstellungen des Pools. Wenn die CPU im Limitzeitraum immer über dem Grenzwert liegt, wird die Limitaktion ausgeführt. Dort gibst du dann KillW3wp an. Da es in dem Moment eh zu spät ist für die Sessions, ist es dann auch egal.
PS: du kannst auch in der SQL-DB im Aktivitätsmonitor schauen ob es Querys gibt die hängen, gelockt sind oder einfach ewig benötigen.
-
ich mag es wie bei dem ding alles von klebeband gehalten wird und die carbonoptik folie überall falten wirft. Ist halt ein Prototyp, aber das Marketing scheint zu funktionieren







VmWare Netzwerkadapter ausversehen entfernt
in Systemadministratoren und Netzwerktechniker
Geschrieben
also auch noch "verbunden"?
dann füg die karte doch mal manuell hinzu, treiber dafür sollten ja noch da sein.