tkreutz2
User
-
Registriert
-
Letzter Besuch
Alle Beiträge von tkreutz2
-
Der ursprüngliche Beitrag wurde von mir bereits öffentlich eingeordnet. Mehr habe ich dazu nicht hinzuzufügen.
-
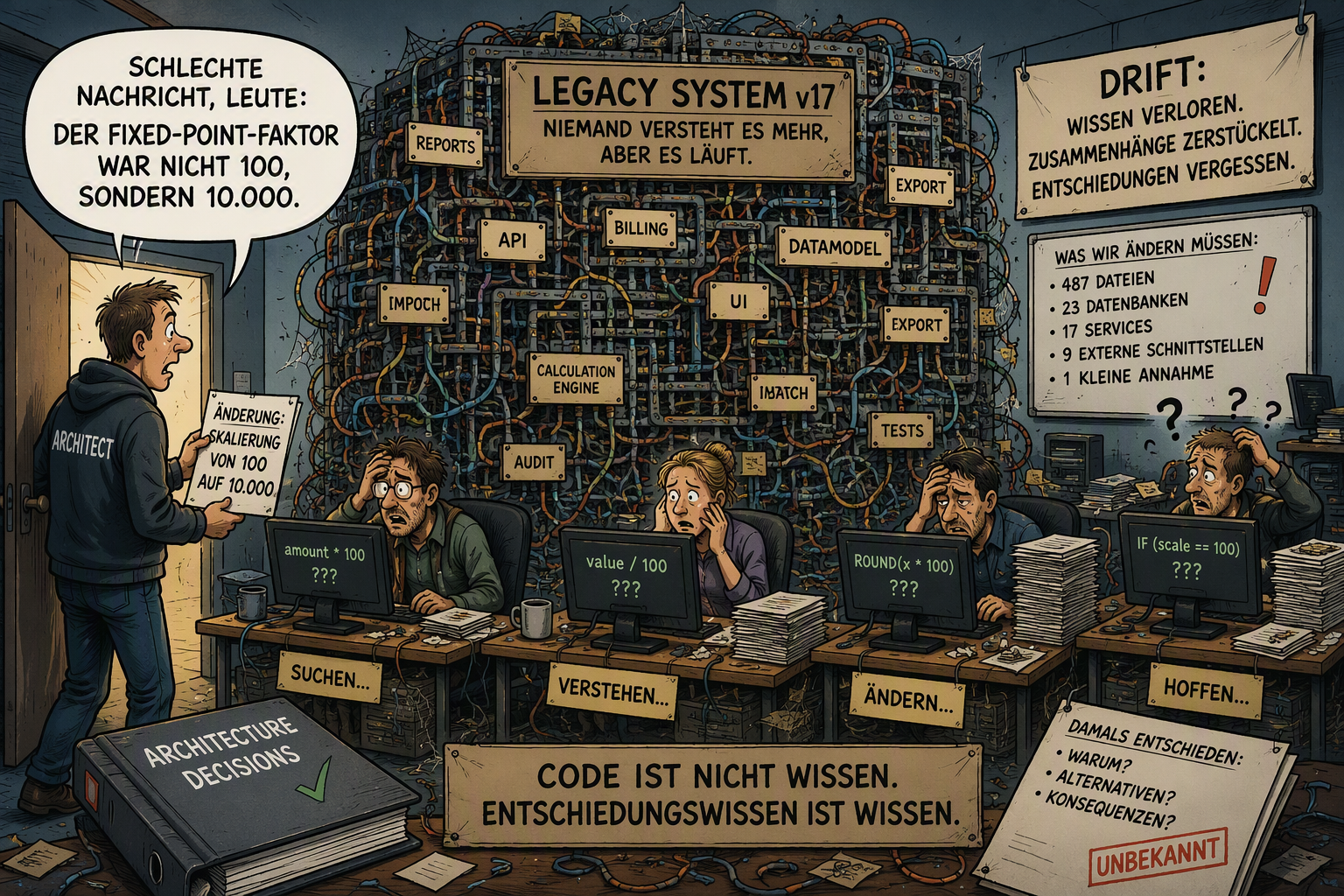
Vergesst den Beitrag bitte, die Idee dahinter war gut, aber die Ki-gestützte Unterstützung schlecht. Da ich den Ausgangsbeitrag nicht mehr löschen kann, kann ich das nur in dieser Form kommentieren. Tut mir leid, war die Idee, ein Thema in einem Bild zu visualisieren, was leider in die Hose ging. Meine ursprüngliche Idee war eigentlich eine Analogie zu einem Reel, was in Social Media existiert, bei dem ein Saal von Mönchen die Bibel mit der Hand transkribieren und dann der Chef kommt und sagt, wir haben leider eine kleine Änderung, der Name (von jemandem der in der ganzen Bibel durchgend genannt wird) ist doch nicht X sondern Y. Die Aufgabe der Ki war eigentlich dieses Thema in einem Bild zu visualisieren, dass kleine Änderungsanforderungen große Folgen nach sich ziehen können. Da wir mit Ki-Themen in neue Bereich vordringen und "glauben" die Produktivität steigern zu können, aber dabei vergessen, dass dadurch auch Nebeneffekte entstehen können, wollte ich eine Analogie von zwei Themen in einem Bild haben. Das ging leider in die Hose, das Bild ist jetzt völlig überladen, enthält Fehler in der mathematischen Darstellung und das Kernthema kann auch nicht mehr visualisiert werden. Also ein Fail, wenn ich so wollte. Mir ist das auch erst später klar geworden, als ich das Bild noch einmal genauer betrachtet hatte. Das große Projekt, an dem ich immer noch arbeite, ist das Thema Ki gestützte Entscheidungsräume. Auf diesem Gebiet konnte ich den letzten 3 Monaten ein Menge Artefakte erzeugen, die ich noch am sortieren bin. Wen es interessiert, den kann ich gerne per PN einen aktuellen Stand dazu senden. In diesem Sinne ! Schönes Wochenende Allen !
-
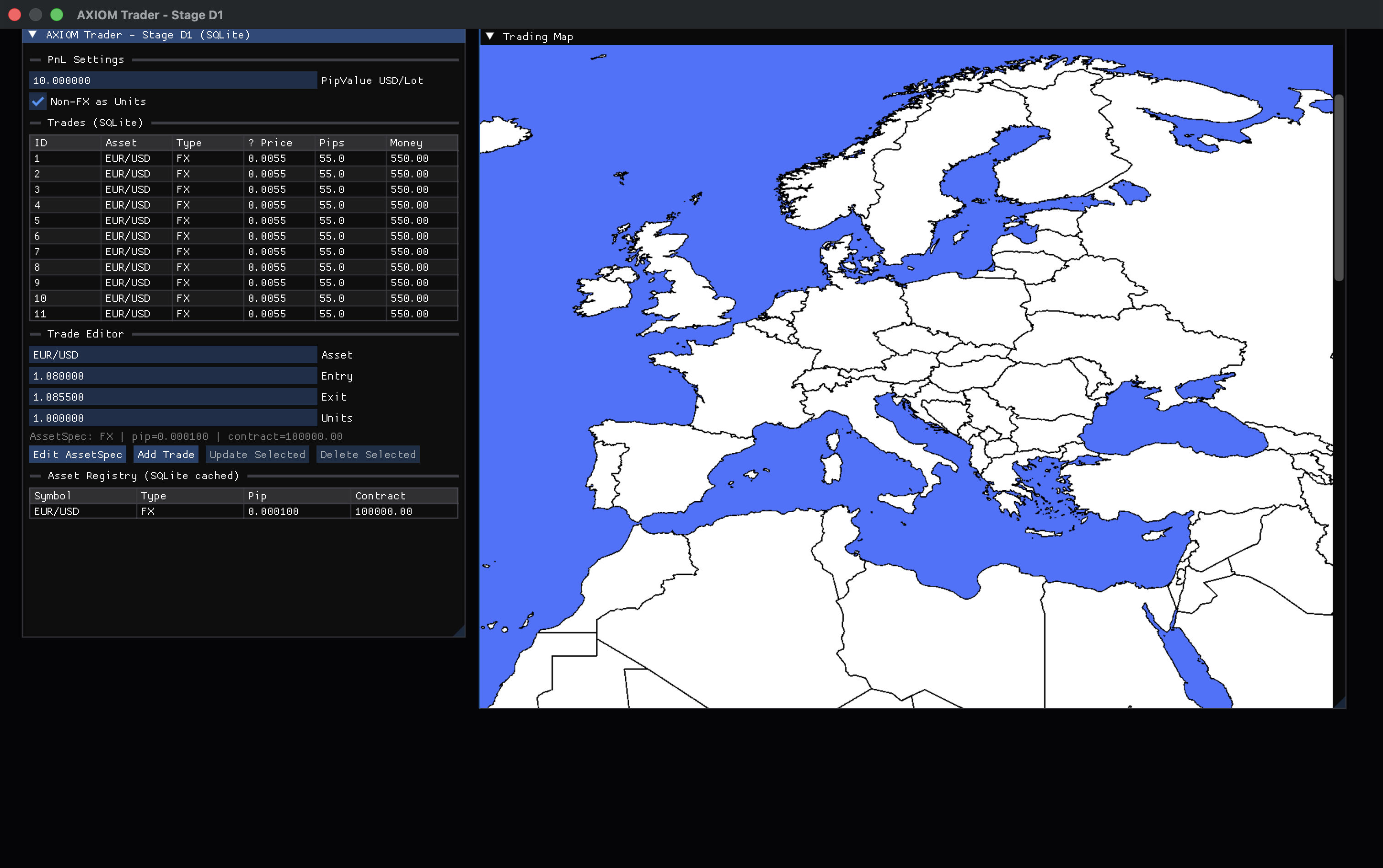
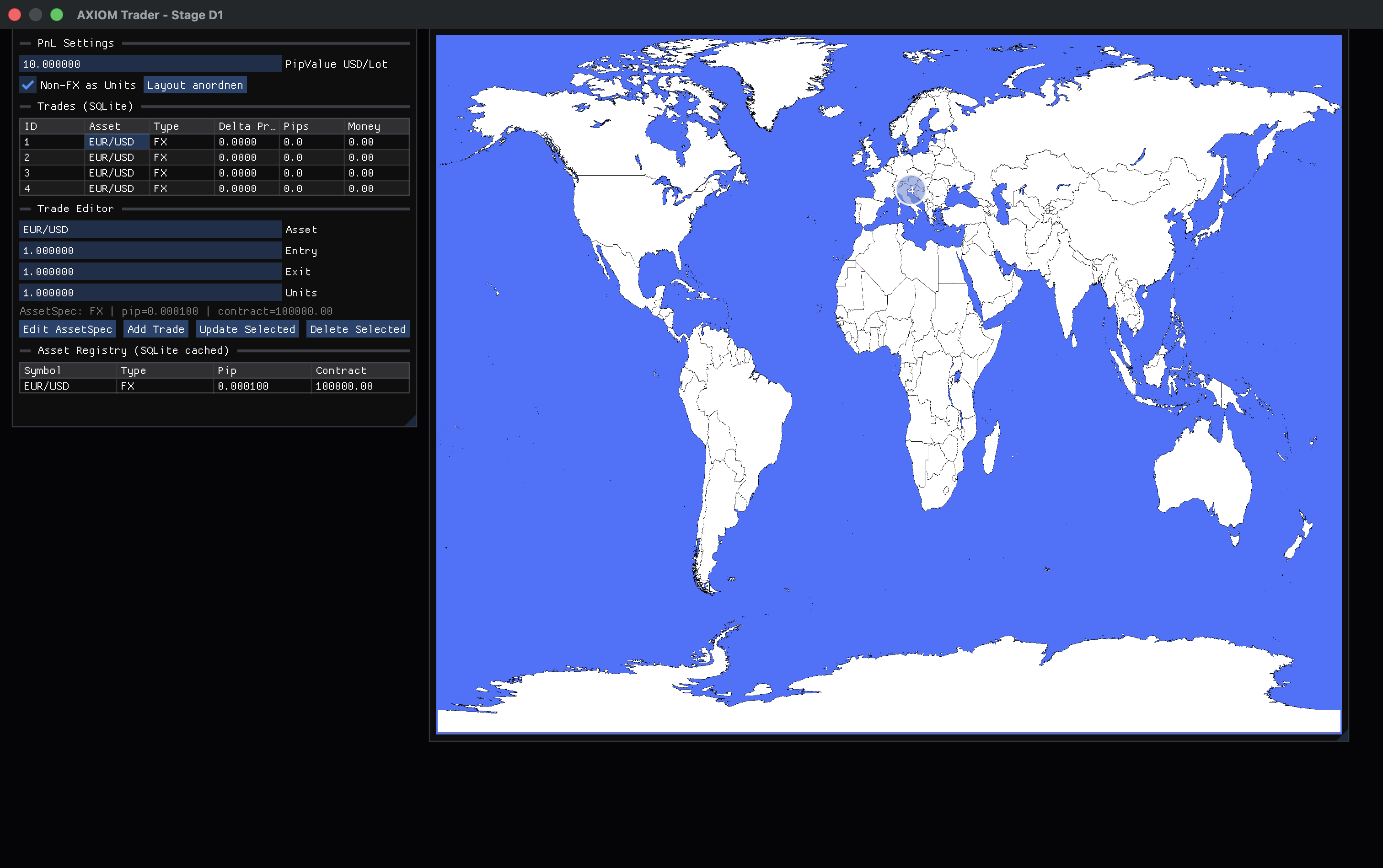
Hallo zusammen, ich beschäftige mich seit einiger Zeit mit der Analyse von Fachinformatiker-Projektanträgen und den dazugehörigen Diskussionen, insbesondere bei Grenzfällen. (Mit Hilfe eines Ki-Modells). Dabei ist mir aufgefallen, dass viele Bewertungen stark über Begriffe wie: - Komplexität - Umfang - Entscheidungsspielraum - Technikanteil geführt werden. Ich habe deshalb versucht, ein einfaches Prüfmodell zu entwickeln, das die bisherigen Beobachtungen strukturierter beschreibt. Die zentrale Hypothese lautet: > Nicht die Entscheidungstiefe ist der erste Prüfpunkt, sondern der Berufsbild-Fit der eigentlichen Kernaktivität. Das Modell arbeitet aktuell mit folgender Prüfkette: Netto-Kernaktivität ↓ Berufsbild-Fit ↓ Entscheidungstiefe ↓ Skalierung ↓ Votum ## Kerngedanke Zunächst wird versucht, die tatsächliche Kernarbeit eines Projekts zu bestimmen. Dabei werden Produktnamen und Buzzwords gedanklich entfernt. Beispiele: - SharePoint - SQL Server - Cisco - Microsoft 365 - Power Platform sagen zunächst wenig über das Berufsbild aus. Entscheidend ist die Frage: > Welche fachliche Arbeit wird eigentlich durchgeführt? Beispiele: ### Eher Fachinformatiker Systemintegration - Infrastrukturintegration - Serverbetrieb - Netzwerkdesign - Systemhärtung - Rechte- und Berechtigungskonzepte - Betriebs- und Sicherheitskonzepte ### Eher Fachinformatiker Anwendungsentwicklung - Workflowlogik - Datenmodellierung - Formularlogik - Geschäftsprozessabbildung - Status- und Freigabelogiken - Anwendungsverhalten ## Daraus ergibt sich eine These Ein Projekt kann - technisch anspruchsvoll, - komplex, - und entscheidungsreich sein, aber trotzdem für das gewählte Berufsbild ungeeignet sein. Umgekehrt kann ein Projekt mit gutem Berufsbild-Fit zunächst zu dünn wirken, aber durch fachlich passende Vertiefung tragfähig werden. ## Beispiel Ein Projekt auf Basis von Microsoft 365 oder SharePoint ist nicht automatisch ein FiSi-Projekt. Die entscheidende Frage wäre: > Besteht die Kernarbeit in Bereitstellung, Integration, Betrieb und Absicherung der Plattform? oder > Besteht die Kernarbeit in Workflowentwicklung, Prozessmodellierung, Formular- und Geschäftslogik? Je nach Antwort könnte derselbe Produktname zu unterschiedlichen Berufsbild-Einordnungen führen. ## Offene Fragen Mich würde interessieren: 1. Haltet ihr die Trennung von Berufsbild-Fit und Entscheidungstiefe für sinnvoll? 2. Habt ihr Beispiele, bei denen ein Projekt wegen des falschen Kompetenzraums abgelehnt wurde, obwohl genügend Entscheidungen vorhanden waren? 3. Wo seht ihr Schwächen dieses Ansatzes? 4. Welche Gegenbeispiele würden das Modell widerlegen? Mein Ziel ist ausdrücklich nicht, eine IHK-Regel zu formulieren, sondern ein Analysemodell zur Diskussion zu stellen. Ich freue mich über Kritik, Gegenbeispiele und Falsifikationen. Muster_PA.pdf@hellerKopf Ich glaube, mein Punkt wird schnell etwas härter gelesen, als ich ihn eigentlich gemeint habe. Mir ging es weniger darum, Juniors pauschal die Fähigkeit abzusprechen, sondern eher um die aktuelle Situation im Zusammenspiel aus Ausbildung, Praxis und den sich verändernden Anforderungen. Wir haben gerade einen ziemlich starken Wandel – insbesondere durch KI. Gleichzeitig hängen Ausbildung und Qualifizierung naturgemäß immer etwas hinterher. Die spannende Frage ist für mich deshalb eher: Wie lange dauert es, bis das Wissen, das heute eigentlich schon gebraucht wird, bei den aktuell Ausgebildeten wirklich ankommt und verinnerlicht ist? Das betrifft ja nicht nur Juniors, sondern genauso bestehende Teams. Der Unterschied ist nur, dass erfahrene Leute neue Werkzeuge schneller auf vorhandene Erfahrung aufsetzen können. Daraus ergibt sich für mich dieser Effekt: Kurzfristig setzen Unternehmen stärker auf erfahrene Kräfte + KI, weil es einfach schneller Wirkung zeigt. Aber im Hintergrund entsteht damit ein gewisser zeitlicher Versatz zwischen: dem, was gebraucht wird und dem, was vermittelt wird Und genau das finde ich gerade spannend – weniger die Frage, wer etwas „kann“ oder „nicht kann“.Danke dir für den Einwand – vor allem den letzten Punkt sehe ich ziemlich ähnlich. Ich merke selbst, dass meine Aussage schnell in Richtung „KI macht alles einfacher“ gelesen wird. So war sie eigentlich nicht gemeint. Mein Eindruck ist eher: Der Einstieg wird einfacher, aber das eigentliche Problem verschiebt sich nur. Früher hast du Fehler im Code gehabt – heute hast du sie eine Ebene drüber, in der Systemdefinition. Und die sind meistens deutlich schwerer zu greifen. Was du zum Thema Ausbildung schreibst, würde ich sofort unterschreiben. Ich habe mich damit selbst mal etwas intensiver beschäftigt, weil ich genau da eine ziemliche Lücke sehe. Mein Eindruck ist: Wir bilden aktuell oft eher „Plattform-Nutzer“ aus als Leute, die Systeme wirklich verstehen oder gestalten können. Viele Lernumgebungen sind so gebaut, dass sie Komplexität verstecken – was für den Einstieg gut ist, aber langfristig auch dazu führt, dass ein echtes Systemverständnis gar nicht erst entsteht. Das wird mit KI aus meiner Sicht eher kritischer als besser. Wenn du Systeme nicht verstehst, kannst du auch nicht beurteilen, was die KI da eigentlich produziert. In dem Sinne sehe ich KI nicht als Ersatz für Fachkräfte, sondern eher als Verstärker: Gute Leute werden deutlich produktiver – aber ohne fundiertes Verständnis wird es schnell unübersichtlich. Die Diskussion um Qualifizierung hinkt da aktuell auf jeden Fall hinterher.Dieses Problem kenne ich nur zu gut und einer meiner ehemaligen Chefs hat es am besten klassifiziert. Man nennt es das "Haben-Wollen-Syndrom". Es wird kein Tag im Leben des Admins geben, der friedlich verläuft, sobald der ERSTE Mitarbeiter etwas hat, was ein anderer Mitarbeiter nicht hat. Dabei ist es Sch...Egal, ob es der größere Monitor, der Drucker, die Workstation oder sonst was ist. Aus dem Grund funktioniert IT auch nur dann in diesem Bereich erfolgreich, wenn es of der gleichen organisatorischen Ebene agiert, wie alle anderen. Wenn andere Abteilungen beispielsweise einen GF im Vorstand haben zu einem Thema, muss es die IT auch haben. Ist das nicht der Fall, wird eine solche IT sich niemals gegen andere innerhalb der Organisation durchsetzen können, weil nie Kommunikation auf Augenhöhe stattfinden wird. Und das ist ein grundsätzliches Problem der betrieblichen Organisation, seit der Erfindung der Betriebswirtschaft im akademischen Bereich. Im Grunde genommen sind sehr viele Probleme in der IT Kommunikationsprobleme und die eigentliche Herausforderungen neben dem fachlichen Wissen im Laufe einer IT-Karriere wird es immer sein, Kommunikationsprobleme zu lösen.Es ist eigentlich ganz einfach, für einen Standard Arbeitsplatz mit Office und Windows reicht auch ein Standard System aus, z.B. von HP oder auch Lenovo. https://www.notebooksbilliger.de/lenovo+thinkcentre+neo+50q+tiny+12ln008mge+889739 Wenn jemand mehr braucht, hat er halt keinen Standard Arbeitsplatzplatz und man muss dann sowieso eine an die Aufgaben / Arbeitsplatz angepasste Konfiguration z.B. Workstation machen. Wir haben ein System im Homeoffice meiner Lebensgefährtin, welches äquivalent zu ihrem Arbeitsplatz System konfiguriert worden ist (16 GB RAM), bisher gab es noch keine Probleme. (Windows 11 + Office 365 Premium Abo). Okay, wenn sich Systemanforderungen ändern z.B. durch neues Windows, neue Anwendungen, dann muss man sowieso wieder neu bewerten, in der Regel spätestens nach 4 Jahren, wenn der PC / Arbeitsplatz abgeschrieben ist. (zu Hause deutlich längere Nutzungszeit). Für Poweranwendungen hat meine Lebensgefährtin noch einen Laptop mit stärkerer Ausstattung, aber wie gesagt, der Desktop ist noch nicht an seine Grenzen gekommen. Man kann Skeptikern ja die Möglichkeit geben, einfach mal ein System auszuprobieren. Da würde ich auch nichts groß messen oder Metriken erfassen, entweder es reicht, oder es reicht nicht. Als IT-Abteilung müsst Ihr ja wissen, welche Apps sonst noch im Einsatz sind und/oder ob es irgendwo ein Nadelöhr gibt. Die meisten Sachen kristallisieren sich eh vermutlich eher im Praxisbetrieb raus, als in der Theorie. Deswegen würde ich empfehlen, rechtzeitig zu dokumentieren und zu inventarisieren. (Auch aus Sicht der Apps, damit ggf. bei künftigen Anforderungen Änderungen in der Beschaffung rechtzeitig berücksichtigt werden können).Guter Punkt – und ich glaube, genau da liegt der eigentliche Kern der ganzen Diskussion. Du beschreibst im Grunde das klassische Problem der Softwareentwicklung: Spezifikation und Implementierung driften auseinander – selbst wenn man sich noch so viel Mühe gibt. Der Unterschied, den ich im Projekt gerade konkret sehe (AXIOM Trader): Bei menschlichen Entwicklern wird ein Teil dieser Lücke meist durch Erfahrung und Intuition kompensiert. Bei der KI fällt diese Kompensation komplett weg – sie setzt exakt das um, was spezifiziert ist, inklusive aller Lücken. Das führt zu einem interessanten Effekt: → Architekturfehler werden nicht mehr „verdeckt“, sondern sofort sichtbar und reproduzierbar. Ich habe das im Projekt relativ deutlich gesehen: Der größte Fehler war am Ende kein Bug im Code, sondern ein fehlender Datenfluss bei eigentlich korrekten Komponenten. Das wäre in einem klassischen Team vermutlich länger „mitgeschleppt“ worden. Deshalb sehe ich KI weniger als Ersatz für Entwickler, sondern eher als Verstärker für Architekturqualität: - saubere Spezifikation → sehr gute Ergebnisse - unscharfe Spezifikation → zuverlässig schlechte Ergebnisse Dein Punkt zur Planungsphase passt da perfekt rein. Das Bottleneck verschiebt sich meiner Meinung nach von der Implementierung hin zur Definition von: - Zuständen - Datenflüssen - Invarianten Ich versuche das aktuell über relativ harte Guardrails + Pre-Check-Systeme zu erzwingen. Der Code ist da fast nur noch „Konsequenz der Architektur“. Was mich interessieren würde: Hast du in deinen Projekten Ansätze gesehen, wie man diese Spec-Drift systematisch in den Griff bekommt? Also eher methodisch (z. B. ArchUnit, Contracts, formale Constraints etc.) – unabhängig von KI?Genau das ist für mich auch der entscheidende Punkt. Ich sehe das weniger als Frage „KI vs. Mensch“, sondern als Frage der notwendigen Präzision in der Architektur. Bei menschlichen Entwicklern können unklare oder unvollständige Vorgaben oft durch Erfahrung und Kreativität ausgeglichen werden. Das System bleibt trotzdem funktionsfähig. Bei KI funktioniert das nicht. Sie setzt exakt das um, was spezifiziert ist – inklusive aller Lücken. Für mich führt das zu der Konsequenz, dass Architektur und Spezifikation deutlich präziser und strukturierter gedacht werden müssen, wenn man KI ernsthaft einsetzen will. Mein Ansatz mit dem AXIOM-Projekt geht genau in diese Richtung: Systeme so zu entwerfen, dass Zustände, Datenflüsse und Abhängigkeiten möglichst deterministisch und nachvollziehbar bleiben, anstatt sich auf implizite Annahmen zu verlassen. In dem Sinne passt der Vergleich eigentlich sehr gut – nur dass die fehlende „Kompensation“ der KI die Schwächen der Architektur deutlich sichtbarer macht.Kurzes Update zum Projekt – inzwischen ist einiges passiert. Ich bin mittlerweile aus der reinen Experimentphase raus und habe das System einmal komplett refaktorisiert und stabilisiert. ## 🔧 Stand aktuell Die komplette Pipeline ist jetzt durchgängig: SQLite → Core → UI → Rendering Das hatte ich am Anfang tatsächlich nicht sauber geschlossen – das System hatte einen klassischen "Silent Failure": → Daten waren korrekt vorhanden → wurden aber nicht dargestellt Am Ende war das kein Bug, sondern ein Architekturproblem. ## 🧠 Wichtigste Änderung: Determinismus Ich habe im Rahmen des Refactorings eine harte Entscheidung getroffen: → vollständiges Verbot von float/double im Core Stattdessen läuft alles über ein eigenes Fixed-Point System auf int64-Basis. Grund: - reproduzierbare Ergebnisse - keine Rundungsfehler - plattformunabhängig ## 🧱 Architektur Ich habe die Struktur jetzt komplett klar gezogen: - Core (C++20, deterministisch, ohne UI) - Mapping Layer (DB → Core) - SQLite (DAO Pattern) - UI (Dear ImGui) - Rendering (Metal) Wichtig: Kein Layer kennt Funktionen eines anderen, die er nicht kennen darf. ## 🔧 Refactoring-Erkenntnis Der spannendste Punkt war ehrlich gesagt: Der größte Fehler im System war kein Code-Fehler, sondern ein fehlender Datenfluss. Das hat man erst gesehen, als alles „eigentlich korrekt“ war. ## 🌍 Ergebnis - Trades werden jetzt korrekt aus SQLite geladen - im Core deterministisch berechnet - im UI dargestellt - und auf der Weltkarte visualisiert ## 🚀 Nächster Schritt - Async DB Worker (kein I/O im UI Thread) - Interaktion auf der Map (Zoom / Selection) - Weiter Richtung Simulation / Constraints statt Logging ## 🧠 Fazit bisher Die eigentliche Schwierigkeit ist nicht: „Kann KI Code schreiben?“ sondern: „Kann man die Architektur so präzise definieren, dass KI gar nicht falsch arbeiten kann?“ Falls Interesse besteht, kann ich gerne nochmal detaillierter auf das Refactoring eingehen – das war tatsächlich der lehrreichste Teil.
 Kurzes Update dazu: Ich habe die daraus entstandene Architektur-Anpassung inzwischen sauber in das ADR-0004 überführt und versioniert. Konkret wurde dort jetzt explizit festgehalten, dass: __int128 keine valide Grundlage für Cross-Platform-Code ist und alle entsprechenden Operationen über Compiler-Guards bzw. Intrinsics abgesichert werden müssen Das war im ursprünglichen ADR so nicht sauber formuliert und ist erst durch den Pre-Check sichtbar geworden. Für mich bestätigt das aktuell den Ansatz ganz gut: → reale Probleme führen zu architektonischen Präzisierungen, nicht nur zu Code-Fixes.Hallo @Wodar Hospur, guter Punkt – das wirkt auf den ersten Blick tatsächlich wie ein Widerspruch, ist aber im Kern eine bewusste Designentscheidung, die ich gerade aufgrund eines KI‑Prechecks angepasst habe. Zur 64‑bit vs. 128‑bit Frage: Im ADR ist bewusst festgelegt: Persistenz / Datenmodell → int64_t (Fixed Point, skalierte Ganzzahlen) 128‑bit → nur als intermediäre Rechenhilfe (Multiply/Divide), nicht als Data-Type Das Problem ist durch den Pre‑Check jetzt sichtbar geworden: Damit verletze ich mein eigenes Blender-/DNA-Prinzip: Das ist kein Optimierungsproblem, sondern ein architektonischer Regelbruch. Deshalb die Anpassung: 64‑bit bleibt der definierte Datenraum 128‑bit wird nicht mehr als „implizit vorhanden“ angenommen sondern über: Compiler-Guards oder platform-spezifische Intrinsics (_umul128 etc.) explizit behandelt Das ADR ist an der Stelle aktuell noch nicht nachgeführt – das ist genau der Punkt, den dieser Pre‑Check sichtbar gemacht hat.Hallo @hellerKopf , exakt an diesem Punkt schließt sich der Kreis zu meinem neuen Pre-Check-System. Du hast vollkommen recht: Wenn ich den Code genauso mühsam Zeile für Zeile prüfen muss, habe ich zeitlich nichts gewonnen. Genau deshalb zwinge ich die KI, die Beweislast umzukehren und das Konformitäts-Audit vorab selbst zu schreiben. Als menschlicher Architekt lese ich nicht mehr kopflos C++ Code, sondern prüfe primär die Plausibilität der von der KI gelieferten Beweiskette gegen meine Invarianten. Und hier ist der direkte Praxis-Beweis, wie dieses System ein rein menschliches Review schlägt: Ich habe die KI über meine Pipeline das Refactoring der Festkomma-Arithmetik (ADR-0004) in die Sandbox docs/pre-checks/0004-fixed-point-review.md generieren lassen. Beim Überfliegen des von der KI geschriebenen Audits fiel der Blick sofort auf Kapitel 4: „Grenzen und Risiken – Compiler-Unterstützung“. Die KI stellte dort in ihrem eigenen Audit fest: „Implementierung nutzt int128. Wenn der Compiler keine int128-Unterstützung bietet (z. B. MSVC ohne Emulation), schlägt die Compilation fehl.“ Einem menschlichen Junior-Entwickler (und Hand aufs Herz: auch vielen Senioren!) wäre dieser plattformspezifische Fehler beim schnellen Tippen unter macOS niemals aufgefallen. Sie hätten den Code eingecheckt, und das Windows-Build-System wäre Stunden später auf die Nase geflogen. Weil meine Pipeline die KI aber dazu zwingt, ein eigenes Risiko-Audit abzuliefern, wurde diese architektonische Sollbruchstelle sichtbar, bevor auch nur eine einzige Zeile Code live in den Core geflossen ist. Ich habe die KI aufgrund ihres eigenen Audits nun angewiesen, ein plattformunabhängiges Fallback via Compiler-Guards und x64-Hardware-Intrinsics (_umul128 / _udiv128) für den MSVC-Compiler auf Windows einzubauen, um das Blender-Prinzip (vollkommene OS-Unabhängigkeit) zu wahren. Der Code sieht im Pre-Check für Windows nun so aus: Vollständiger Source ist im Repository
Kurzes Update dazu: Ich habe die daraus entstandene Architektur-Anpassung inzwischen sauber in das ADR-0004 überführt und versioniert. Konkret wurde dort jetzt explizit festgehalten, dass: __int128 keine valide Grundlage für Cross-Platform-Code ist und alle entsprechenden Operationen über Compiler-Guards bzw. Intrinsics abgesichert werden müssen Das war im ursprünglichen ADR so nicht sauber formuliert und ist erst durch den Pre-Check sichtbar geworden. Für mich bestätigt das aktuell den Ansatz ganz gut: → reale Probleme führen zu architektonischen Präzisierungen, nicht nur zu Code-Fixes.Hallo @Wodar Hospur, guter Punkt – das wirkt auf den ersten Blick tatsächlich wie ein Widerspruch, ist aber im Kern eine bewusste Designentscheidung, die ich gerade aufgrund eines KI‑Prechecks angepasst habe. Zur 64‑bit vs. 128‑bit Frage: Im ADR ist bewusst festgelegt: Persistenz / Datenmodell → int64_t (Fixed Point, skalierte Ganzzahlen) 128‑bit → nur als intermediäre Rechenhilfe (Multiply/Divide), nicht als Data-Type Das Problem ist durch den Pre‑Check jetzt sichtbar geworden: Damit verletze ich mein eigenes Blender-/DNA-Prinzip: Das ist kein Optimierungsproblem, sondern ein architektonischer Regelbruch. Deshalb die Anpassung: 64‑bit bleibt der definierte Datenraum 128‑bit wird nicht mehr als „implizit vorhanden“ angenommen sondern über: Compiler-Guards oder platform-spezifische Intrinsics (_umul128 etc.) explizit behandelt Das ADR ist an der Stelle aktuell noch nicht nachgeführt – das ist genau der Punkt, den dieser Pre‑Check sichtbar gemacht hat.Hallo @hellerKopf , exakt an diesem Punkt schließt sich der Kreis zu meinem neuen Pre-Check-System. Du hast vollkommen recht: Wenn ich den Code genauso mühsam Zeile für Zeile prüfen muss, habe ich zeitlich nichts gewonnen. Genau deshalb zwinge ich die KI, die Beweislast umzukehren und das Konformitäts-Audit vorab selbst zu schreiben. Als menschlicher Architekt lese ich nicht mehr kopflos C++ Code, sondern prüfe primär die Plausibilität der von der KI gelieferten Beweiskette gegen meine Invarianten. Und hier ist der direkte Praxis-Beweis, wie dieses System ein rein menschliches Review schlägt: Ich habe die KI über meine Pipeline das Refactoring der Festkomma-Arithmetik (ADR-0004) in die Sandbox docs/pre-checks/0004-fixed-point-review.md generieren lassen. Beim Überfliegen des von der KI geschriebenen Audits fiel der Blick sofort auf Kapitel 4: „Grenzen und Risiken – Compiler-Unterstützung“. Die KI stellte dort in ihrem eigenen Audit fest: „Implementierung nutzt int128. Wenn der Compiler keine int128-Unterstützung bietet (z. B. MSVC ohne Emulation), schlägt die Compilation fehl.“ Einem menschlichen Junior-Entwickler (und Hand aufs Herz: auch vielen Senioren!) wäre dieser plattformspezifische Fehler beim schnellen Tippen unter macOS niemals aufgefallen. Sie hätten den Code eingecheckt, und das Windows-Build-System wäre Stunden später auf die Nase geflogen. Weil meine Pipeline die KI aber dazu zwingt, ein eigenes Risiko-Audit abzuliefern, wurde diese architektonische Sollbruchstelle sichtbar, bevor auch nur eine einzige Zeile Code live in den Core geflossen ist. Ich habe die KI aufgrund ihres eigenen Audits nun angewiesen, ein plattformunabhängiges Fallback via Compiler-Guards und x64-Hardware-Intrinsics (_umul128 / _udiv128) für den MSVC-Compiler auf Windows einzubauen, um das Blender-Prinzip (vollkommene OS-Unabhängigkeit) zu wahren. Der Code sieht im Pre-Check für Windows nun so aus: Vollständiger Source ist im Repository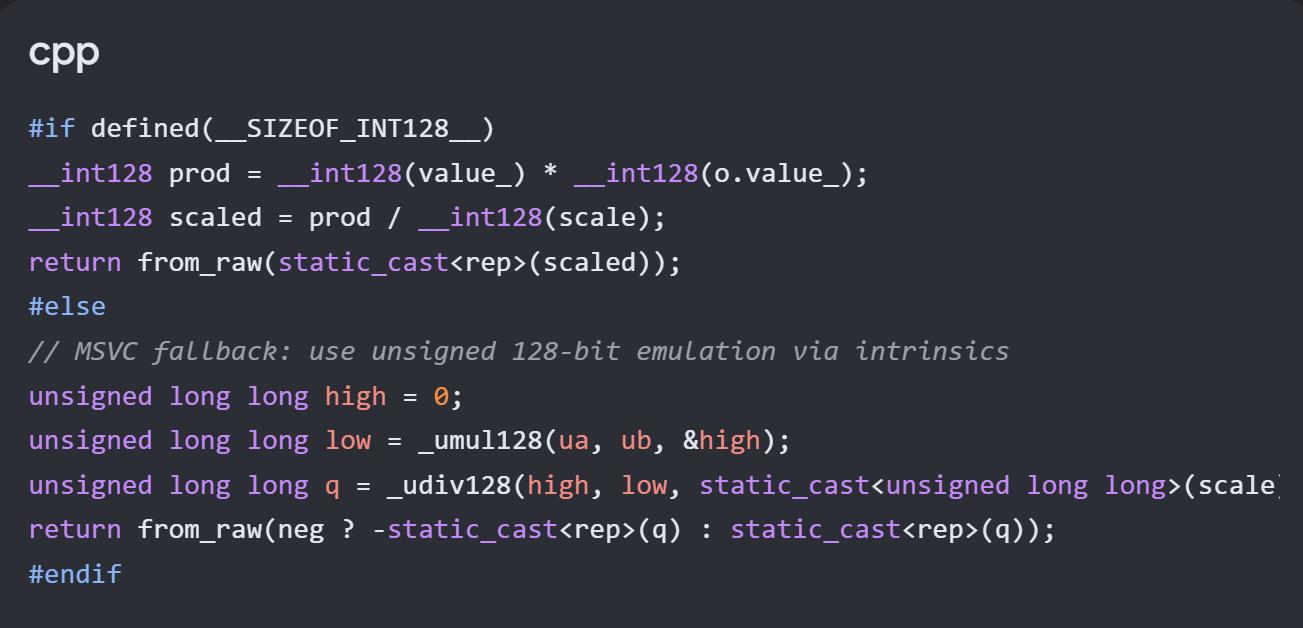 Hallo zusammen, ich möchte die methodische Diskussion hier direkt aufgreifen und euch den nächsten Evolutionsschritt meines Experiments vorstellen. Die Frage, wie man die unzuverlässige „Junior-KI“ bändigt und reproduzierbare „Senior-Ergebnisse“ erzielt, hat mich zu einem radikalen Umdenken im Workflow gezwungen. Reines Prompt-Tuning in der IDE reicht ab einer gewissen Projektgröße nicht mehr aus. Wenn die KI direkt im Quellcode arbeitet, entstehen die von euch völlig zu Recht kritisierten Brüche (wie die Float-Leichen oder redundante Implementierungen). Ich habe daher ein automatisiertes KI-QS- und Pre-Check-System direkt in das Repository integriert. Die KI arbeitet ab sofort nicht mehr direkt auf den Quellcodedateien, sondern durchläuft eine strikte Vier-Phasen-Governance-Pipeline: Die Invarianten (decisions/prompt-guardrails.md): Hier sind die harten Architektur-Gesetze (wie das plattformunabhängige Blender-Prinzip, das absolute Float-Verbot und das Allokations-Verbot im Hotpath) maschinenlesbar für die KI hinterlegt. Die Sandbox (Pre-Check-Phase): Die KI darf bestehenden C++ Code nicht mehr direkt verändern. Sie muss jeden Code-Vorschlag zuerst in einer isolierten Review-Datei im neuen Verzeichnis docs/pre-checks/ablegen. Der Konformitäts-Beweis: In dieser Review-Datei muss die KI vorab schriftlich und logisch beweisen, dass ihr generierter Code-Vorschlag keine einzige Regel der Guardrails verletzt. Die Dialog-Historisierung: Parallel dazu wird der vollständige Konversations- und Prompt-Verlauf als Markdown-Dokument im Git-Repository versioniert. Wer das Repo klont, sieht somit in Zukunft nicht nur das fertige Produkt, sondern die lückenlose Evolution der "Mensch-Maschine-Diskussion". Die Praxisprobe läuft gerade: Ich habe die von euch angestoßene Architekturentscheidung ADR-0004 (Einführung von plattformunabhängiger FixedPoint-Arithmetik via int64_t zur Eliminierung aller Floats) ins Repo gepusht. Die Windows-Dev-Umgebung auf meinem Handheld steht. Die Entwickler-KI hat nun den Auftrag erhalten, das großflächige Core-Refactoring exakt nach diesem neuen Pre-Check-Muster in docs/pre-checks/0004-fixed-point-review.md vorzubereiten. Sobald die KI den Code und ihren Konformitätsbeweis dort abgelegt hat, werde ich als menschlicher Chef-Architekt das finale Review durchführen, bevor der Code live in den Xcode-Core fließt. Ich halte euch über die Ergebnisse dieses kontrollierten KI-Einsatzes auf dem Laufenden!Hallo @hellerKopf , deine strukturierte Gegenüberstellung der LLM-Antworten deckt das Kernproblem perfekt auf. Sie zeigt genau das, was ich die „KI-Varianz-Krise“ (oder das Overconfidence-Pattern) nenne: Die KI optimiert auf Eloquenz, nicht auf Wahrheit (p. 6). Sie listet im Chat brav alle 20 RAII-Regeln auf, bricht diese aber im echten Code-Generierungsprozess, sobald der Kontext komplexer wird (p. 6). Sie verhält sich exakt wie ein Junior-Entwickler in der Theorieprüfung vs. Praxis. Um die KI auf das Level eines Seniors zu hieven, reicht rein esoterisches Prompt-Tuning oder das Erweitern von Text-Guidelines ab einem gewissen Punkt nicht mehr aus. Man muss die Software-Architektur selbst als Kontrollmechanismus aufbauen. Ich habe für diesen Zweck ein übergeordnetes Framework entwickelt, das ich als „Living Architecture Library“ (basierend auf einem SYNAPSE-CPP Kern) in meinen Projekten einsetze (pp. 1, 19). Das Ziel ist eine KI-Governance, die auf einem Drei-Instanzen-Modell basiert (pp. 1, 9): Instanz 1: Der Generator (Probabilistisch): Das ist die Entwickler-KI (wie Copilot oder Claude) (p. 9). Ihr Output ist grundsätzlich „untrusted“ (p. 9). Sie liefert lediglich Lösungs-Hypothesen im Akkord (Junior-Level) (p. 9). Instanz 2: Der Falsifikator (Antagonist): Ein separates KI-Agenten-System mit dem expliziten, destruktiven Auftrag: „Suche systematisch nach Fehlern, Memory Leaks und Logikbrüchen im Code von Instanz 1“ (p. 9). Instanz 3: Der Evaluator (Deterministisch): Ein harter, in C++20 geschriebener Kern, der nicht mehr auf Wahrscheinlichkeiten basiert (p. 9). Er prüft den generierten Code und die Systemzustände gegen unverrückbare mathematische und architektonische Invarianten (p. 9). Angewandt auf dein RAII-Beispiel: Wenn Instanz 1 Code generiert, jagt Instanz 3 (der Evaluator) diesen durch eine automatisierte Kette (z. B. zyklomatische Komplexitätsprüfung \(\le 10\), Clang-Tidy Matcher auf new/delete und automatisierte Test-Suites) (p. 9). Verletzt die KI eine dieser Invarianten, wird der Code rigoros verworfen, und das System triggert mit dem Fehlerprotokoll eine neue Iteration (p. 17). Erst durch diese deterministische Kontrollschicht (Instanz 3) wird die unzuverlässige „Junior-KI“ gezwungen, Code auf absolutem „Senior-Niveau“ abzuliefern (p. 9). Das System sichert sich selbst ab (p. 19). Dieses Prinzip der Markt- und Code-Governance nutzen wir auch im Axiom Trader (p. 16), um die KI-Autonomie mathematisch zu bändigen. Wenn dich (oder die anderen) die genauen mathematischen Invarianten-Prüfungen dieses Setups interessieren, kann ich das gerne mal näher aufdröseln!Hallo @hellerKopf , du triffst hier einen extrem wichtigen Punkt. Ein Experiment ohne klare Metriken und Definition von „Grenzen“ läuft Gefahr, rein anekdotisch zu bleiben. Vielen Dank für diesen methodischen Anstoß! Zu deiner Frage, was ich genau erfahren will und wo ich die Grenzen ziehe: Meine primäre Hypothese ist: Kann eine KI komplexe, plattformspezifische Systemarchitekturen (wie hardwarenahes Metal-Rendering gepaart mit deterministischer Trading-Logik) fehlerfrei verwalten, wenn der Mensch ausschließlich abstrakte Regeln vorgibt? Die Grenze ziehe ich da, wo die KI architektonische Brüche erzeugt (wie die von dir/Claude entdeckte Dreifach-Implementierung der Persistenz), weil der Kontext-Fenster-Horizont oder das logische Verständnis für das Gesamtgefüge reißt. Zu den Metriken (Quantitativ & Qualitativ): Da ich das Projekt alleine in meiner Freizeit hochziehe, sind vollumfängliche Langzeitstudien schwer machbar. Aber ich tracke für mich bereits einige Daten, die ich gerne im Verlauf des Projekts teilen kann: Entwicklungszeit (Time-to-Market): Wie viele Minuten vergehen vom Architektur-Konzept in der ARCHITECT.md bis zum kompilierbaren Feature in Xcode? (Spoiler: Bei UI-Prototypen extrem schnell, bei Refactorings im Core bricht die Geschwindigkeit ein). Fehlerrate / Regressionen: Wie oft führt ein neuer Prompt dazu, dass eigentlich funktionierende Features an anderer Stelle unbemerkt wegbrechen? Zu deiner Frage bezüglich der Formulierungen (Best-Practice-to-generate): Ja, absolut! Das ist im Grunde der Kern der ARCHITECT.md. Ich teste intensiv, welche Detailtiefe die KI benötigt. Meine bisherige Erkenntnis: Allgemeine Phrasen wie "Schreibe performanten Code" bewirken gar nichts. Die KI benötigt restriktive, imperative Verbote und mathematische Konzepte. Ein Beispiel: Erst als ich die Regel "Nutze RAII" durch die konkrete Anweisung "Nutze ausnahmslos std::unique_ptr oder Stack-Allokation für Ressourcen in src/core/" ersetzt habe, sank die Memory-Leak-Rate im generierten Code gegen Null. Ich dokumentiere diese Erkenntnisse parallel. Wenn daraus am Ende eine Art strukturiertes „Best-Practice-Template“ für C++20-Generierung entsteht, teile ich das sehr gerne hier im Forum! Die "feine Klinge" (Fixed-Point-Math für die Währungen) schlage ich übrigens gerade ein – ich poste das Update, sobald die Pipeline fehlerfrei steht.Vielen Dank für das ehrliche und detaillierte Feedback! Genau das ist der springende Punkt: Es gibt hier definitiv noch einiges zu tun. Einige Funktionen und optimierte Codepfade sind aktuell auch bewusst temporär ausgeschaltet oder als Prototyp hinterlegt, während an ganz anderen Baustellen parallel weitergearbeitet wird. Man muss bei diesem Projekt massiv berücksichtigen, dass hier absolut iterativ vorgegangen wird. Der Code, den du jetzt siehst, ist der Zustand eines fließenden Übergangs. Insgesamt ist das ein völlig neuer, experimenteller Workflow, den es so in klassischen, (echten) Produktiv-Projekten eins zu eins wahrscheinlich nie geben wird – da dort von Anfang an ganz andere Code-Reviews und statische Analysen greifen. Es ist und bleibt ein Experiment, um die Grenzen der rein KI-gesteuerten Generierung auszuloten. Aber dafür ist es immerhin schon ein ganzes Stück weit gekommen und liefert eine stabile, native Metal-Oberfläche auf macOS, auf der wir jetzt die feineren architektonischen Klingen (wie Fixed-Point für Geldwerte und Allokations-Stopps im Hotpath) iterativ schleifen können. Ich halte euch hier über die nächsten Refactoring-Schritte auf dem Laufenden!Hallo zusammen, ich möchte hier ein aktuelles Pilotprojekt von mir teilen und zur Diskussion stellen. Es geht um die Frage, wie weit man die Code-Generierung durch KI treiben kann, wenn man als Mensch konsequent nur noch die Rolle des Software-Architekten einnimmt. Das Projekt: Axiom Trader (aktuell v0.4.0-alpha) – ein hochperformantes Handelssystem für macOS. Das Experiment: Ich schreibe keine einzige Zeile Code selbst. Jede Implementierung, jeder Bugfix, das Speichermanagement und die Render-Pipelines werden komplett von der KI umgesetzt. Der Tech-Stack: * Sprachen: C++20 und Objective-C++ (Gewichtung ca. 52% zu 45% im Repo). * UI/Rendering: Ein "Blender-Modell". Dear ImGui eingebettet in ein natives CAMetalLayer-Hosting-View für minimale Latenzen unter macOS 15/16. * Plattform: Optimiert für Apple Silicon (M-Chips), Zero-Overhead-Schleifen, explizite Metal-Pipeline-Zustände. Wie funktioniert das in der Praxis? Der Schlüssel zum Erfolg ist eine extrem strikte ARCHITECT.md im Repository. Diese fungiert als unumstößliches Regelwerk (Guardrails) für die KI. Die wichtigsten Regeln, die das System stabil halten: 1. Strikte Schichtentrennung: Der Core src/core/) enthält die deterministische Logik und darf absolut keine UI- oder Grafik-Header (ImGui, Metal) importieren. 2. RAII-Zwang: Ressourcenmanagement erfolgt ausnahmslos über RAII, um Speicherlecks im C++-Code von vornherein auszuschließen. 3. UI-Scoping: Dynamische ImGui-Tabellen müssen zwingend über ID-Scoping ImGui::PushID / PopID) abgesichert werden, um State-Konflikte im UI-Thread zu verhindern. Bisherige Erkenntnis: Wenn die architektonischen Leitplanken eng und mathematisch präzise genug gesteckt sind, neigt die KI nicht zu Halluzinationen. Stattdessen liefert sie hochoptimierten, sauberen C++20-Code, der sich in Xcode tadellos kompilieren lässt. Das Build-System von Xcode 16 verarbeitet diesen hybriden C++/Obj-C++ Mix extrem performant. Das Projekt steuert gerade auf die Version v0.5.x zu (Anbindung von SQLite für die Persistenz und Textur-Streaming via stb_image.h in die Metal-Buffer). Mich würde euer Feedback interessieren: Hat jemand von euch schon ähnliche Projekte umgesetzt, bei denen die KI vollständige* Code-Autonomie hatte? * Wie steuert ihr die Code-Qualität bei generiertem C++20-Code (Stichwort: statische Codeanalyse vs. Prompt-Guardrails)? * Seht ihr bei so einem "Architekt (Mensch) vs. Developer (KI)"-Modell langfristig die Zukunft in der Anwendungsentwicklung? Wer sich das Regelwerk oder den Code genauer ansehen möchte: Das Projekt ist Open Source auf GitHub (Link packe ich in die Kommentare/Signatur). Freue mich auf eine sachliche Diskussion! GitHubGitHub - tkreutz0-cmyk/axiom-trader: The Vision: A high-p...The Vision: A high-performance, deterministic trading journal built on the "Blender Model"—prioritizing full GUI control, local data sovereignty, and zero App Store friction. - tkreutz0-c...Würde ich nicht empfehlen, als Referenz zu nehmen. Das Mehrfamilienhaus meiner Eltern, was im Jahr 2018 verkauft worden ist, ist nie in einem der Portale erschienen bis heute, weder bei Vermietung noch bei Verkauf. Das ist ähnlich wie "Preisvorstellungen" bei Ebay zu abenteuerlichen Preisen. Ob die Preise real erzielt wurden, müsste erst mal verifiziert werden. Selbst abgeschlossene Auktionen können kompletter Fake sein z.B. aus Marketinggründen. Meine Erfahrung aus der Zeit, wo meine Eltern noch selbst vermietet haben ist die, dass die Portale unseriöse und lästige Spam Anfragen aller Art nachziehen, weswegen meistens über andere Wege vermietet wird. Heißt konkret, Konditionen- und Preise sind alles andere als Transparent. Es ist so ähnlich wie bei Stellenanzeigen, während die Jobs real bereits längst vergeben wurden oder sogar überhaupt nicht existieren. Aus dem Grund ist die Frage nach einer validen Quelle durchaus berechtigt.Was verstehst Du denn unter "Branchenwechsel" ? - Du schreibst was von komplett neuem Ausbildungsberuf (was man natürlich machen kann), aber das hat primär ja erst mal nichts mit der Branche zu tun. Branchenwechsel wäre in meinen Augen z.B. der Wechsel von einem Industriebetrieb zu einer Bank (Dienstleistung), oder von Handel zu Energie & Umwelt. Ohne regionalen Bezug, wird hier kaum jemand einen Tipp geben können. Aber die Frage nach Flexibilität (also Bereitschaft, dorthin umzuziehen, wo ggf. ein anderes Angebot vorhanden ist), spielt schon eine Rolle. Warum hat Dir denn der Betrieb, der Dich ausgebildet hat, kein Jobangebot gemacht ? Das wären alles so die Fragen, die mir bei einem Bewerbungsgespräch einfallen würden. Du kannst ja mal anonymisiert Deine Bewerbungsunterlagen hochladen und hier prüfen lassen. Vielleicht gibt es ein paar Punkte, die optimiert werden können. Ansonsten wurde ja der Tipp gegeben, Kontakte auszubauen. Gibt es denn irgendwelche Projekte, die Du in Deinem persönlichen Showcase hast (z.B. Git Repo) und anhand interessierte Leute einen Einblick in Deine Skills bekommen können ?Formell ist bei Umschülern der Bildungsträger der "Ausbildungsbetrieb" der Praktikumsbetrieb stellt lediglich einen Praktikumsplatz, auch wenn vor Ort Leute sind, die Ausbildungsberechtigt sind, ist es nicht vergleichbar wie in regulären Ausbildungsverträgen, die mit Betrieben direkt geschlossen werden. Aus dem Grund ist die Wahl des Praktikumsbetriebes bei Umschülern immer mit einem ungleich höherem Risiko verbunden, als bei regulären Ausbildungsverhältnissen. Was man tun kann, ist auf jeden Fall mit dem Praktikumsbetrieb ein Gespräch führen, ob eine Prüfungswiederholung möglich wäre, wenn die Prüfung nicht bestanden würde. Die meisten Betriebe zeigen sich hier kulant. Problem bei Umschülern ist halt, dass sie keine Ausbildungsvergütung vom Praktikumsbetrieb bekommen und ohne finanzielle Mittel sich kaum einer einen zweiten oder dritten Schuss leisten können. Da müsste auch die ARGE oder Rententräger, oder wer auch immer die Kosten trägt, die Zustimmung zu geben. Mir sind Fälle bekannt, in denen dann der Bildungsträger für Abschlußprojekte eingesprungen ist als Praktikumsbetrieb, aber auch das ist keine Regel. Frage an den Threadsteller wäre hier, um welchen Ausbildungsschwerpunkt es sich handelt. (FiSi, FiAE). Da von "eigener Hardware" die Rede ist, gehe ich mal von FiSi aus. Hier könnte das von mir geschilderte Szenario greifen, dass im äußersten Notfall der Bildungsträger einspringt. Mein Rat, schnell die entsprechenden Gespräche suchen am Besten sofort, ohne Zögern. Ja, PoC gilt auch für FiAE - aber im Zweifelsfall immer nach Absprache mit der regionalen IHK. Und noch ein Hinweis ein den TE - Du musst Deine Abschlussarbeit selbst erstellen. Deine Kollegen sind da raus, sobald die Uhr tickt, das wäre auch in jedem anderem Betrieb nicht anders. Viel Glück !Unbedingt
Hallo zusammen, ich möchte die methodische Diskussion hier direkt aufgreifen und euch den nächsten Evolutionsschritt meines Experiments vorstellen. Die Frage, wie man die unzuverlässige „Junior-KI“ bändigt und reproduzierbare „Senior-Ergebnisse“ erzielt, hat mich zu einem radikalen Umdenken im Workflow gezwungen. Reines Prompt-Tuning in der IDE reicht ab einer gewissen Projektgröße nicht mehr aus. Wenn die KI direkt im Quellcode arbeitet, entstehen die von euch völlig zu Recht kritisierten Brüche (wie die Float-Leichen oder redundante Implementierungen). Ich habe daher ein automatisiertes KI-QS- und Pre-Check-System direkt in das Repository integriert. Die KI arbeitet ab sofort nicht mehr direkt auf den Quellcodedateien, sondern durchläuft eine strikte Vier-Phasen-Governance-Pipeline: Die Invarianten (decisions/prompt-guardrails.md): Hier sind die harten Architektur-Gesetze (wie das plattformunabhängige Blender-Prinzip, das absolute Float-Verbot und das Allokations-Verbot im Hotpath) maschinenlesbar für die KI hinterlegt. Die Sandbox (Pre-Check-Phase): Die KI darf bestehenden C++ Code nicht mehr direkt verändern. Sie muss jeden Code-Vorschlag zuerst in einer isolierten Review-Datei im neuen Verzeichnis docs/pre-checks/ablegen. Der Konformitäts-Beweis: In dieser Review-Datei muss die KI vorab schriftlich und logisch beweisen, dass ihr generierter Code-Vorschlag keine einzige Regel der Guardrails verletzt. Die Dialog-Historisierung: Parallel dazu wird der vollständige Konversations- und Prompt-Verlauf als Markdown-Dokument im Git-Repository versioniert. Wer das Repo klont, sieht somit in Zukunft nicht nur das fertige Produkt, sondern die lückenlose Evolution der "Mensch-Maschine-Diskussion". Die Praxisprobe läuft gerade: Ich habe die von euch angestoßene Architekturentscheidung ADR-0004 (Einführung von plattformunabhängiger FixedPoint-Arithmetik via int64_t zur Eliminierung aller Floats) ins Repo gepusht. Die Windows-Dev-Umgebung auf meinem Handheld steht. Die Entwickler-KI hat nun den Auftrag erhalten, das großflächige Core-Refactoring exakt nach diesem neuen Pre-Check-Muster in docs/pre-checks/0004-fixed-point-review.md vorzubereiten. Sobald die KI den Code und ihren Konformitätsbeweis dort abgelegt hat, werde ich als menschlicher Chef-Architekt das finale Review durchführen, bevor der Code live in den Xcode-Core fließt. Ich halte euch über die Ergebnisse dieses kontrollierten KI-Einsatzes auf dem Laufenden!Hallo @hellerKopf , deine strukturierte Gegenüberstellung der LLM-Antworten deckt das Kernproblem perfekt auf. Sie zeigt genau das, was ich die „KI-Varianz-Krise“ (oder das Overconfidence-Pattern) nenne: Die KI optimiert auf Eloquenz, nicht auf Wahrheit (p. 6). Sie listet im Chat brav alle 20 RAII-Regeln auf, bricht diese aber im echten Code-Generierungsprozess, sobald der Kontext komplexer wird (p. 6). Sie verhält sich exakt wie ein Junior-Entwickler in der Theorieprüfung vs. Praxis. Um die KI auf das Level eines Seniors zu hieven, reicht rein esoterisches Prompt-Tuning oder das Erweitern von Text-Guidelines ab einem gewissen Punkt nicht mehr aus. Man muss die Software-Architektur selbst als Kontrollmechanismus aufbauen. Ich habe für diesen Zweck ein übergeordnetes Framework entwickelt, das ich als „Living Architecture Library“ (basierend auf einem SYNAPSE-CPP Kern) in meinen Projekten einsetze (pp. 1, 19). Das Ziel ist eine KI-Governance, die auf einem Drei-Instanzen-Modell basiert (pp. 1, 9): Instanz 1: Der Generator (Probabilistisch): Das ist die Entwickler-KI (wie Copilot oder Claude) (p. 9). Ihr Output ist grundsätzlich „untrusted“ (p. 9). Sie liefert lediglich Lösungs-Hypothesen im Akkord (Junior-Level) (p. 9). Instanz 2: Der Falsifikator (Antagonist): Ein separates KI-Agenten-System mit dem expliziten, destruktiven Auftrag: „Suche systematisch nach Fehlern, Memory Leaks und Logikbrüchen im Code von Instanz 1“ (p. 9). Instanz 3: Der Evaluator (Deterministisch): Ein harter, in C++20 geschriebener Kern, der nicht mehr auf Wahrscheinlichkeiten basiert (p. 9). Er prüft den generierten Code und die Systemzustände gegen unverrückbare mathematische und architektonische Invarianten (p. 9). Angewandt auf dein RAII-Beispiel: Wenn Instanz 1 Code generiert, jagt Instanz 3 (der Evaluator) diesen durch eine automatisierte Kette (z. B. zyklomatische Komplexitätsprüfung \(\le 10\), Clang-Tidy Matcher auf new/delete und automatisierte Test-Suites) (p. 9). Verletzt die KI eine dieser Invarianten, wird der Code rigoros verworfen, und das System triggert mit dem Fehlerprotokoll eine neue Iteration (p. 17). Erst durch diese deterministische Kontrollschicht (Instanz 3) wird die unzuverlässige „Junior-KI“ gezwungen, Code auf absolutem „Senior-Niveau“ abzuliefern (p. 9). Das System sichert sich selbst ab (p. 19). Dieses Prinzip der Markt- und Code-Governance nutzen wir auch im Axiom Trader (p. 16), um die KI-Autonomie mathematisch zu bändigen. Wenn dich (oder die anderen) die genauen mathematischen Invarianten-Prüfungen dieses Setups interessieren, kann ich das gerne mal näher aufdröseln!Hallo @hellerKopf , du triffst hier einen extrem wichtigen Punkt. Ein Experiment ohne klare Metriken und Definition von „Grenzen“ läuft Gefahr, rein anekdotisch zu bleiben. Vielen Dank für diesen methodischen Anstoß! Zu deiner Frage, was ich genau erfahren will und wo ich die Grenzen ziehe: Meine primäre Hypothese ist: Kann eine KI komplexe, plattformspezifische Systemarchitekturen (wie hardwarenahes Metal-Rendering gepaart mit deterministischer Trading-Logik) fehlerfrei verwalten, wenn der Mensch ausschließlich abstrakte Regeln vorgibt? Die Grenze ziehe ich da, wo die KI architektonische Brüche erzeugt (wie die von dir/Claude entdeckte Dreifach-Implementierung der Persistenz), weil der Kontext-Fenster-Horizont oder das logische Verständnis für das Gesamtgefüge reißt. Zu den Metriken (Quantitativ & Qualitativ): Da ich das Projekt alleine in meiner Freizeit hochziehe, sind vollumfängliche Langzeitstudien schwer machbar. Aber ich tracke für mich bereits einige Daten, die ich gerne im Verlauf des Projekts teilen kann: Entwicklungszeit (Time-to-Market): Wie viele Minuten vergehen vom Architektur-Konzept in der ARCHITECT.md bis zum kompilierbaren Feature in Xcode? (Spoiler: Bei UI-Prototypen extrem schnell, bei Refactorings im Core bricht die Geschwindigkeit ein). Fehlerrate / Regressionen: Wie oft führt ein neuer Prompt dazu, dass eigentlich funktionierende Features an anderer Stelle unbemerkt wegbrechen? Zu deiner Frage bezüglich der Formulierungen (Best-Practice-to-generate): Ja, absolut! Das ist im Grunde der Kern der ARCHITECT.md. Ich teste intensiv, welche Detailtiefe die KI benötigt. Meine bisherige Erkenntnis: Allgemeine Phrasen wie "Schreibe performanten Code" bewirken gar nichts. Die KI benötigt restriktive, imperative Verbote und mathematische Konzepte. Ein Beispiel: Erst als ich die Regel "Nutze RAII" durch die konkrete Anweisung "Nutze ausnahmslos std::unique_ptr oder Stack-Allokation für Ressourcen in src/core/" ersetzt habe, sank die Memory-Leak-Rate im generierten Code gegen Null. Ich dokumentiere diese Erkenntnisse parallel. Wenn daraus am Ende eine Art strukturiertes „Best-Practice-Template“ für C++20-Generierung entsteht, teile ich das sehr gerne hier im Forum! Die "feine Klinge" (Fixed-Point-Math für die Währungen) schlage ich übrigens gerade ein – ich poste das Update, sobald die Pipeline fehlerfrei steht.Vielen Dank für das ehrliche und detaillierte Feedback! Genau das ist der springende Punkt: Es gibt hier definitiv noch einiges zu tun. Einige Funktionen und optimierte Codepfade sind aktuell auch bewusst temporär ausgeschaltet oder als Prototyp hinterlegt, während an ganz anderen Baustellen parallel weitergearbeitet wird. Man muss bei diesem Projekt massiv berücksichtigen, dass hier absolut iterativ vorgegangen wird. Der Code, den du jetzt siehst, ist der Zustand eines fließenden Übergangs. Insgesamt ist das ein völlig neuer, experimenteller Workflow, den es so in klassischen, (echten) Produktiv-Projekten eins zu eins wahrscheinlich nie geben wird – da dort von Anfang an ganz andere Code-Reviews und statische Analysen greifen. Es ist und bleibt ein Experiment, um die Grenzen der rein KI-gesteuerten Generierung auszuloten. Aber dafür ist es immerhin schon ein ganzes Stück weit gekommen und liefert eine stabile, native Metal-Oberfläche auf macOS, auf der wir jetzt die feineren architektonischen Klingen (wie Fixed-Point für Geldwerte und Allokations-Stopps im Hotpath) iterativ schleifen können. Ich halte euch hier über die nächsten Refactoring-Schritte auf dem Laufenden!Hallo zusammen, ich möchte hier ein aktuelles Pilotprojekt von mir teilen und zur Diskussion stellen. Es geht um die Frage, wie weit man die Code-Generierung durch KI treiben kann, wenn man als Mensch konsequent nur noch die Rolle des Software-Architekten einnimmt. Das Projekt: Axiom Trader (aktuell v0.4.0-alpha) – ein hochperformantes Handelssystem für macOS. Das Experiment: Ich schreibe keine einzige Zeile Code selbst. Jede Implementierung, jeder Bugfix, das Speichermanagement und die Render-Pipelines werden komplett von der KI umgesetzt. Der Tech-Stack: * Sprachen: C++20 und Objective-C++ (Gewichtung ca. 52% zu 45% im Repo). * UI/Rendering: Ein "Blender-Modell". Dear ImGui eingebettet in ein natives CAMetalLayer-Hosting-View für minimale Latenzen unter macOS 15/16. * Plattform: Optimiert für Apple Silicon (M-Chips), Zero-Overhead-Schleifen, explizite Metal-Pipeline-Zustände. Wie funktioniert das in der Praxis? Der Schlüssel zum Erfolg ist eine extrem strikte ARCHITECT.md im Repository. Diese fungiert als unumstößliches Regelwerk (Guardrails) für die KI. Die wichtigsten Regeln, die das System stabil halten: 1. Strikte Schichtentrennung: Der Core src/core/) enthält die deterministische Logik und darf absolut keine UI- oder Grafik-Header (ImGui, Metal) importieren. 2. RAII-Zwang: Ressourcenmanagement erfolgt ausnahmslos über RAII, um Speicherlecks im C++-Code von vornherein auszuschließen. 3. UI-Scoping: Dynamische ImGui-Tabellen müssen zwingend über ID-Scoping ImGui::PushID / PopID) abgesichert werden, um State-Konflikte im UI-Thread zu verhindern. Bisherige Erkenntnis: Wenn die architektonischen Leitplanken eng und mathematisch präzise genug gesteckt sind, neigt die KI nicht zu Halluzinationen. Stattdessen liefert sie hochoptimierten, sauberen C++20-Code, der sich in Xcode tadellos kompilieren lässt. Das Build-System von Xcode 16 verarbeitet diesen hybriden C++/Obj-C++ Mix extrem performant. Das Projekt steuert gerade auf die Version v0.5.x zu (Anbindung von SQLite für die Persistenz und Textur-Streaming via stb_image.h in die Metal-Buffer). Mich würde euer Feedback interessieren: Hat jemand von euch schon ähnliche Projekte umgesetzt, bei denen die KI vollständige* Code-Autonomie hatte? * Wie steuert ihr die Code-Qualität bei generiertem C++20-Code (Stichwort: statische Codeanalyse vs. Prompt-Guardrails)? * Seht ihr bei so einem "Architekt (Mensch) vs. Developer (KI)"-Modell langfristig die Zukunft in der Anwendungsentwicklung? Wer sich das Regelwerk oder den Code genauer ansehen möchte: Das Projekt ist Open Source auf GitHub (Link packe ich in die Kommentare/Signatur). Freue mich auf eine sachliche Diskussion! GitHubGitHub - tkreutz0-cmyk/axiom-trader: The Vision: A high-p...The Vision: A high-performance, deterministic trading journal built on the "Blender Model"—prioritizing full GUI control, local data sovereignty, and zero App Store friction. - tkreutz0-c...Würde ich nicht empfehlen, als Referenz zu nehmen. Das Mehrfamilienhaus meiner Eltern, was im Jahr 2018 verkauft worden ist, ist nie in einem der Portale erschienen bis heute, weder bei Vermietung noch bei Verkauf. Das ist ähnlich wie "Preisvorstellungen" bei Ebay zu abenteuerlichen Preisen. Ob die Preise real erzielt wurden, müsste erst mal verifiziert werden. Selbst abgeschlossene Auktionen können kompletter Fake sein z.B. aus Marketinggründen. Meine Erfahrung aus der Zeit, wo meine Eltern noch selbst vermietet haben ist die, dass die Portale unseriöse und lästige Spam Anfragen aller Art nachziehen, weswegen meistens über andere Wege vermietet wird. Heißt konkret, Konditionen- und Preise sind alles andere als Transparent. Es ist so ähnlich wie bei Stellenanzeigen, während die Jobs real bereits längst vergeben wurden oder sogar überhaupt nicht existieren. Aus dem Grund ist die Frage nach einer validen Quelle durchaus berechtigt.Was verstehst Du denn unter "Branchenwechsel" ? - Du schreibst was von komplett neuem Ausbildungsberuf (was man natürlich machen kann), aber das hat primär ja erst mal nichts mit der Branche zu tun. Branchenwechsel wäre in meinen Augen z.B. der Wechsel von einem Industriebetrieb zu einer Bank (Dienstleistung), oder von Handel zu Energie & Umwelt. Ohne regionalen Bezug, wird hier kaum jemand einen Tipp geben können. Aber die Frage nach Flexibilität (also Bereitschaft, dorthin umzuziehen, wo ggf. ein anderes Angebot vorhanden ist), spielt schon eine Rolle. Warum hat Dir denn der Betrieb, der Dich ausgebildet hat, kein Jobangebot gemacht ? Das wären alles so die Fragen, die mir bei einem Bewerbungsgespräch einfallen würden. Du kannst ja mal anonymisiert Deine Bewerbungsunterlagen hochladen und hier prüfen lassen. Vielleicht gibt es ein paar Punkte, die optimiert werden können. Ansonsten wurde ja der Tipp gegeben, Kontakte auszubauen. Gibt es denn irgendwelche Projekte, die Du in Deinem persönlichen Showcase hast (z.B. Git Repo) und anhand interessierte Leute einen Einblick in Deine Skills bekommen können ?Formell ist bei Umschülern der Bildungsträger der "Ausbildungsbetrieb" der Praktikumsbetrieb stellt lediglich einen Praktikumsplatz, auch wenn vor Ort Leute sind, die Ausbildungsberechtigt sind, ist es nicht vergleichbar wie in regulären Ausbildungsverträgen, die mit Betrieben direkt geschlossen werden. Aus dem Grund ist die Wahl des Praktikumsbetriebes bei Umschülern immer mit einem ungleich höherem Risiko verbunden, als bei regulären Ausbildungsverhältnissen. Was man tun kann, ist auf jeden Fall mit dem Praktikumsbetrieb ein Gespräch führen, ob eine Prüfungswiederholung möglich wäre, wenn die Prüfung nicht bestanden würde. Die meisten Betriebe zeigen sich hier kulant. Problem bei Umschülern ist halt, dass sie keine Ausbildungsvergütung vom Praktikumsbetrieb bekommen und ohne finanzielle Mittel sich kaum einer einen zweiten oder dritten Schuss leisten können. Da müsste auch die ARGE oder Rententräger, oder wer auch immer die Kosten trägt, die Zustimmung zu geben. Mir sind Fälle bekannt, in denen dann der Bildungsträger für Abschlußprojekte eingesprungen ist als Praktikumsbetrieb, aber auch das ist keine Regel. Frage an den Threadsteller wäre hier, um welchen Ausbildungsschwerpunkt es sich handelt. (FiSi, FiAE). Da von "eigener Hardware" die Rede ist, gehe ich mal von FiSi aus. Hier könnte das von mir geschilderte Szenario greifen, dass im äußersten Notfall der Bildungsträger einspringt. Mein Rat, schnell die entsprechenden Gespräche suchen am Besten sofort, ohne Zögern. Ja, PoC gilt auch für FiAE - aber im Zweifelsfall immer nach Absprache mit der regionalen IHK. Und noch ein Hinweis ein den TE - Du musst Deine Abschlussarbeit selbst erstellen. Deine Kollegen sind da raus, sobald die Uhr tickt, das wäre auch in jedem anderem Betrieb nicht anders. Viel Glück !Unbedingt